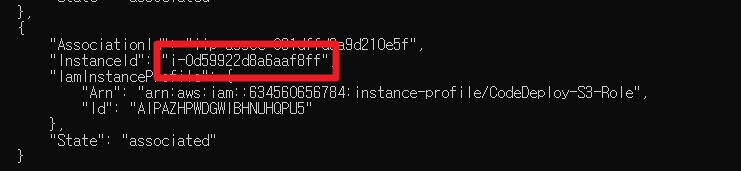
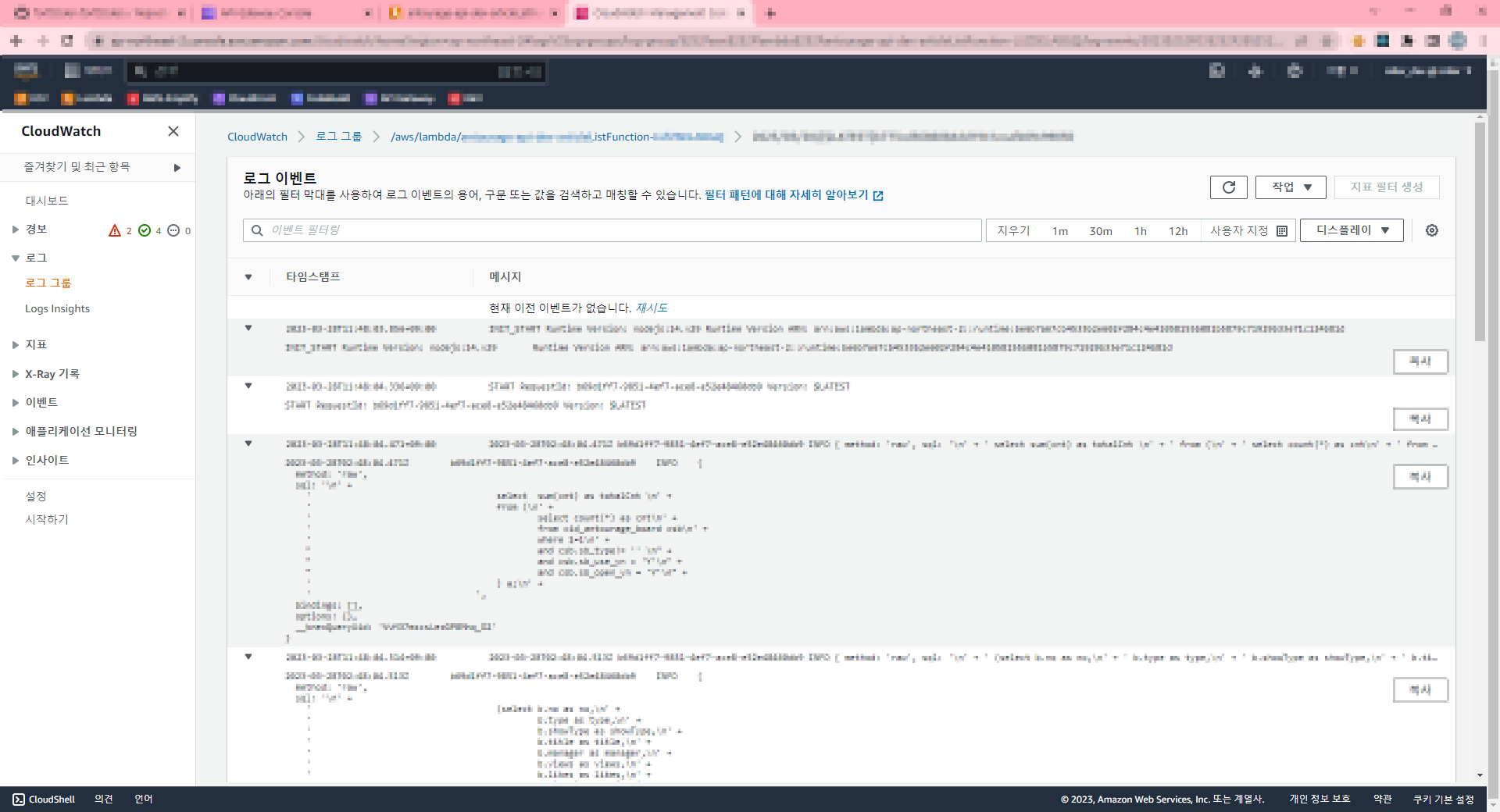
aws에서 ec2 인스턴스에 속한 iam을 변경하는 경우 위와 같은 문구를 만날때가 있다. 근데 찾아보면 'IAM 역할 없음' 선택 후 저장하면 된다고 하는데 그래도 위 에러가 계속 발생하는 경우가 있다. 찾아보니까 이런 경우는 aws cli로 커맨드를 직접 날려서 해결해야한다고 하더라.
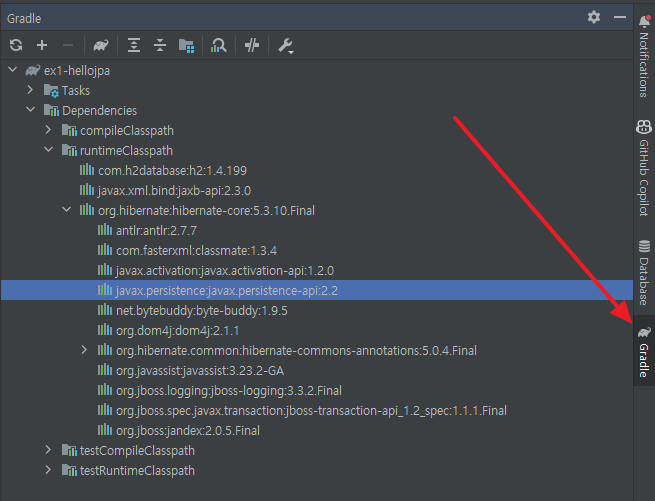
intellij gradle 프로젝트 생성 후, 원하는 dependency가 있는데 설치하는 방법을 안내하겠다.
2. 문제상황
김영한 님의 JPA 강좌를 듣는데 강좌 초기 부분에서 일단 maven으로 하자고 하셨는데, 꼭~~~! 말 안 듣고 gradle로 하는 사람이 있다. 물론 본인도 평소에 gradle로 개발을 해왔기 때문에 말 안 듣고 gradle로 설치하였다. 문제는 원하는 hibernate, h2 database 2개를 설치해야하는데 어떻게 찾아야 하는지 아예 감도 안 잡히는 분들을 위해 간단한 글을 작성해 봤다.
3. 해결방법
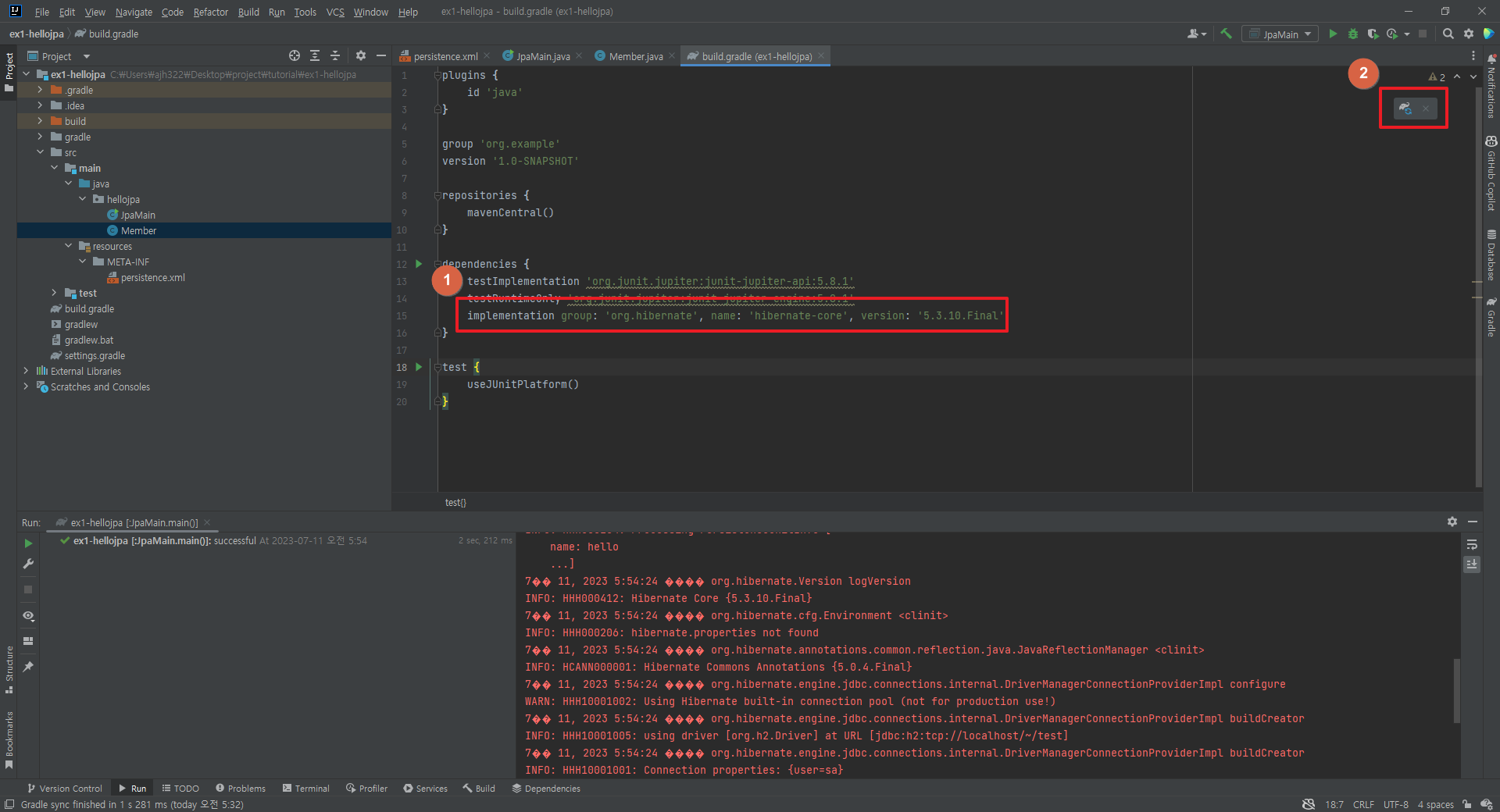
본인이 원하는 dependency의 이름과 버전을 생각해 본다. 해당 강좌에서는 각각 "hibernate 5.3.10.Final", "com.h2database 1.4.199"이다.
구글에 검색한다 gradle depedency "이름 버전"
그러면 가장 첫 번째 게시물로 저 사이트가 나온다.
보면 본인의 상황에 맞는 gradle을 선택하면 gradle.build에 작성해야 하는 코드가 나온다.
16학번, 현재 4학년, 현역이나 중간에 회사 생활을 길게 하다 와서 현재 개발자 경력 7년 차이면서 학교와 회사를 병행 중 창업융합전공으로 복수전공을 했으며, 학점은 관심 없고 졸업하는 것이 목표.
취지
꽤 많은 창업융합전공 수업을 들으며 들었던 생각을 공유하고 예비창업자, 교양으로 창업 수업을 찍먹 해보려는 사람, 기창업자에게 현재 본인의 상황에 맞춰서 좋은 강의를 선택할 수 있도록 도움을 주고자 작성하게 됐다.
수강했던 한양대학교 창업 융합 전공 수업
클라우드비지니스모델 (김현회, 윤준선) 창업실습2(류창완) 창업실습:스타트랙1(강창규) 창업기초:스타트업기업가정신의이해와사례(백필호) 창업실무:모바일게임프로그래밍기초(김지원) 스타트업토크콘서트(류창완) 블록체인과비즈니스모델(이장우) 창업실무:금융DT와핀테크SW기초(이현열) 창업심화:창업마케팅(정진하) 창업심화:스타트업 A to Z(윤준수)
창업 수업을 들어 본 뒤 소감
모든 수업마다 너무 달라서 한마디로 요약할 수 없기에 계속해서 서술해 나갈 것이나, 모든 강의 공통으로 짧게 요약하여 얘기해 보자면 아래와 같다.
"사회에서 만나기 힘들 정도로 대단한 분(사업, 커리어)이 학생들에게 어떠한 방식(학점, 창업, 기술, 인맥)으로든 도움이 될 수 있게끔 고민하여 커리큘럼을 짜서 전수해 주는 시간"
물론 만족스럽지 못한 수업도 있었고 생각보다 기대 이상으로 만족스러웠던 강의도 있었다. 확실한 건 본인이 얼마나 노력하느냐에 따라 아무것도 못 얻거나, 많은 것을 얻을 수 있는 시간이다.(네다꼰)
수강생 본인의 상황에 따라 2가지 조언
학점 중요
만약 프로젝트, 팀플 형태 수업인 경우 학점을 잘 받기 위해서는 '수업에서 얼마나 열심히 하느냐' 보다본인, 팀의 '사업 아이디어가 있고 꽤 디벨롭되어 있는지'가 더 중요하다.
프로젝트, 팀플 형태수업은 시간과 에너지를 많이 뺏어먹는다.
확실히 학점 후한 수업이 따로 존재한다. 수강평을 잘 보고 선택하자.
학점 안 중요
학점이 안 중요한 당신, 앉아 있는 시간이 아까우니 뭐라도 얻어 가려면 좋은 교수님을 택해야 한다. 사실 만나기 전에 수강평만 듣고 좋은 교수님인지 아닌지 판단하는 건 힘들지만 적어도 해당 게시물에 내가 추천한 강의는 꼭 들어볼 것.
인맥을 쌓으려면, 좋은 인재를 발굴하려면 팀플 형태의 강의를 들어라 => 같이 팀플하는 사람뿐만 아니라 다른 팀원과의 교류도 충분히 생긴다. 또한 본인이 의지가 있으면 이론위주 강의보다 팀플 강의가 피곤하지만 좋은 사람을 만나기 쉬운 환경이다.
교수님 인맥 또한 중요하니 가능하면 모든 교수님 수업을 하나씩 듣자 => 앞서 말했다시피 모든 교수님 한 명 한명 특정 분야에서 엄청난 영향력을 갖고 있으며 대부분 한 다리만 건너도 당신이 도움을 받을 수 있는 사람으로 꽉 차있을 것이다.
강의 추천
창업기초:스타트업기업가정신의이해와사례(백필호)
백필호 교수님은 정말 멋있는 분이다. 그것 하나만으로 이 수업을 들을 가치가 있다. 교수님은 정말 창업 생태계에 대한 탄탄한 Insight를 갖고 계시며 정부지원사업의 전문가이시다. 사람 자체도 열정, 친절함, 예의로 가득 찬 것이 느껴진다. 수업 내용은 전반적인 창업에 대한 말씀을 해주시는데 아직 창업에 대해서 잘 모르고 어떤 느낌인지 궁금하다면 추천한다. 멋있는 사람의 멋있는 생각을 배울 수 있는 좋은 기회.
블록체인과비즈니스모델(이장우)
교수님께 죄송하지만 수업이 좋기보다는 해당 수업에서 만난 수강생들이 너무 훌륭해서 적어봤다. 요지는 팀플형태의 수업에서 괜찮게 느껴지는 수강생과 얘기해서 밥이라도 한번 먹어보라
머 대충 이런느낌...?(상대방 남자임) 창업 융합 전공 수업을 통하여 좋은 사람을 많이 만났다.
클라우드비지니스모델 (김현회, 윤준선)
윤준선 대표님께서 IR, 투자에 대한 필드 경험을 바탕으로 재밌고 유익한 경험을 많이 얘기해 주신다. 실제 IR이 어떤 방식으로 흘러가는지, 투자자들이 뭐 하고 어떤 사람인지 조금이나마 알 수 있게 되었다.
창업심화:스타트업 A to Z(윤준수)
교수님이 너무 멋있는 분이라 그 자체만으로 들을 가치가 있다. 그리고 굉장히 특이한 수업이다. 수업의 50%는 윤준수 교수님이 생각하는 '창업이란 이런 것이다...'를 설명하고 조언해 주는 시간이다. 나머지 50%는 본인이 창업 생태계에 몸담으면서 본인이 겪거나 생각한 여러 가지 상황, 사건에 대해서 재조명하여 도움이 될만한 Insight를 정리하여 이를 학생들에게 알려주는 시간이다. 베르나르 베르베르의 상상력 사전과 같은 느낌? 누군가 해당 수업 후기에 수업 내용이 너무 맥락 없이 파편적이라는 지적을 했는데, 나는 그 파편 하나하나가 엄청 와닿는 얘기라서 너무 좋았다.
마치며...
사실 이 글을 처음 쓰게 된 계기는 본인이 감명받은 교수님들에 대한 경의를 표하고 이 감정을 잊지 않고 기리고 싶어서다. 좋은 말씀, 열정, 솔직함, 친절함, 겸손함, 기업가정신 그리고 그 무엇보다도 학생들에게 의미 있는 강의를 하기 위해 행하셨던 그 모든 노력에 감사하고 경의를 표합니다.
람다라는 서비스를 통하여 serverless 구조로 기존의 dedicated 서버 형식 API 또는 백엔드 서버가 없는
본인은 올해로 6년 차 개발자이며, 작년 9월부터 이직했고 회사에 도착해 보니 보통 알고 있던 ec2기반 백엔드 + 프론트 서버의 형태가 아닌 sam(serverless application model) 백엔드 + 클라우드프론트, 앰플리파이를 통한 완전히 aws 서비스만으로 모든 서버의 유지부터 배포를 끝내는 아키텍쳐를 경험했다. 해당 회사에서 지금 4월까지 얼추 6개월정도 해당 아키텍처를 기반으로 신규 프로젝트 구축부터 유지보수를 진행했다. 비록 일시적이지만 게시판, VOD, 회원가입, 결제가 최소한으로 들어간 4개의 프로젝트의 시작부터 종료까지 함께했다.
이 정도면 꽤 실험적이 아닌 실무적으로 aws lambda 서비스를 활용했다고 믿을 수 있지 않을까? 우선 람다는 핵심 서비스의 장기적인 개발 관점에서 탈락이다. 큰 단점이 매우 많이 존재한다. 한번 해볼까? 하는 마음가짐으로 람다를 가볍게 도입하려는 분께는 내가 미리 똥이란 것을 알아넀으니 단호하게 No라고 하겠다.
장점
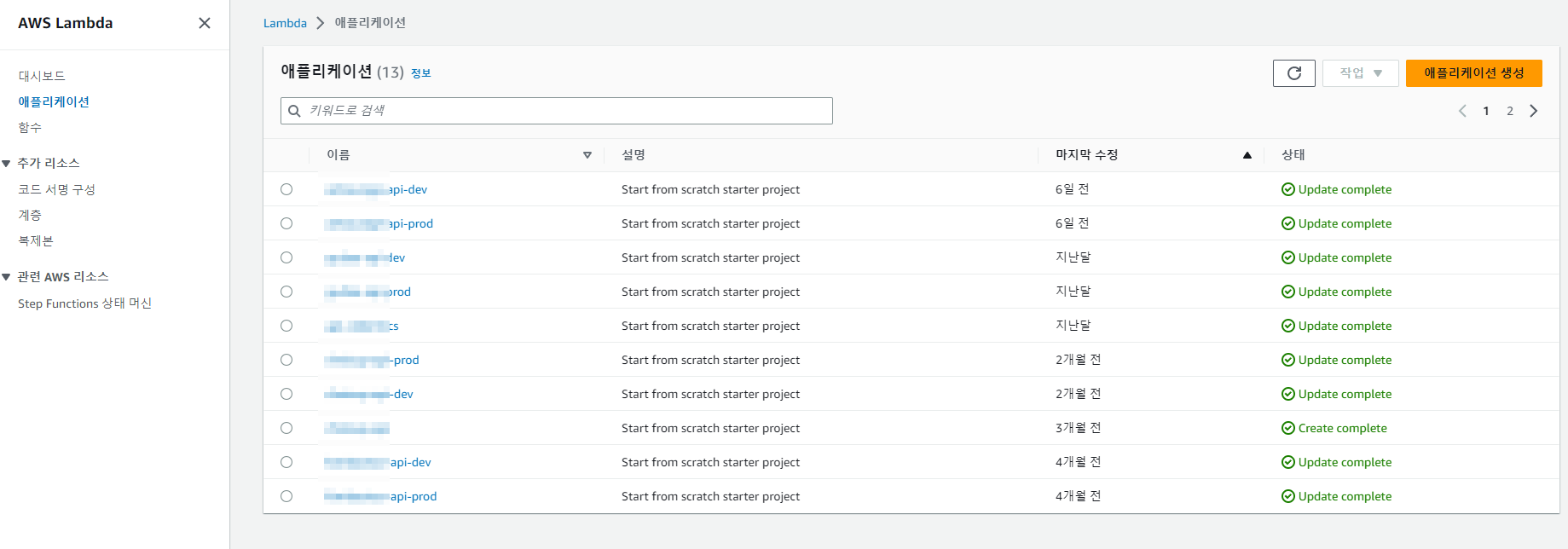
존재하는 모든 API 서버를 한눈에 볼 수 있다.
1. aws에서 콘솔로 관리 : 단순 정보는 조회에 용이
어디에 무엇이 있는지 aws 콘솔에 전부 나와 있기 때문에 알 수 없는 정보란 존재하지 않는다. 말이 어려운데 예를 들자면 프로젝트에 API 서버가 4개가 있고 이를 아무도 모아놓은 docs가 없다고 해보자. aws에 구축해놓았다면 서비스 콘솔에 모든 정보가 바로 뜨기 때문에 한눈에 서비스를 보기에는 빠르고 쉽다.
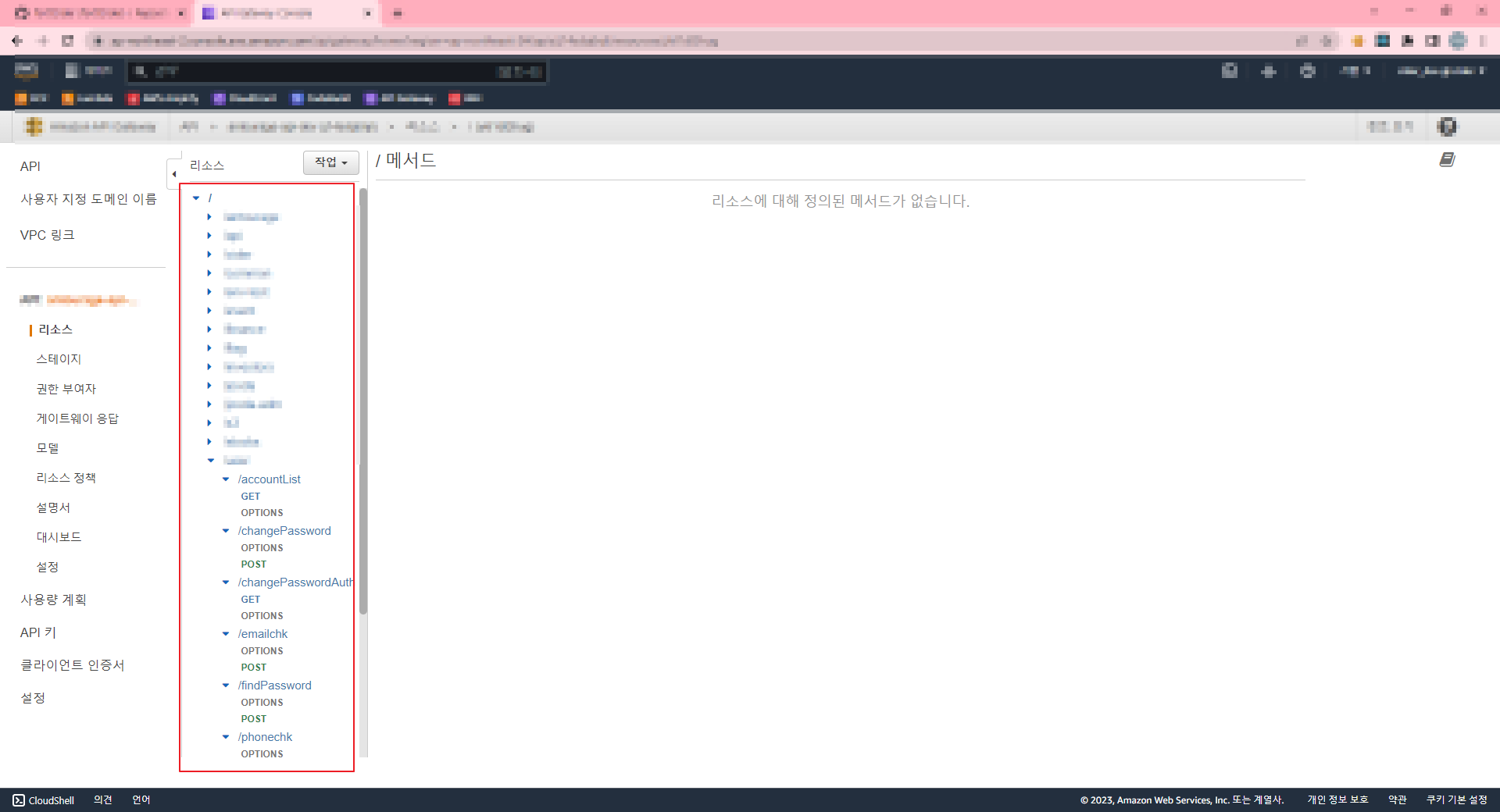
프로젝트에서 결과로 API로 쓰일 함수만 내보낼 수 있으며 등록한 API는 우측 이미지와 같이 콘솔에 표출된다.
2. 함수형 지향, 기능 구현에 집중 할 수 있음
우리가 API 서버를 구축한다고 하면 정말 많은 것을 고려해야 하지만 sam 방식은 정말로 API로 쓰일 핵심 함수만 구축하면 되기 때문에 기능 구현에 초점 집중 할 수 있다. 나아가 모든 기능을 함수로 제공하는 것을 강제하기 때문에 유저는 자연스럽게 재사용, 함수형 개발을 할 수 있다.
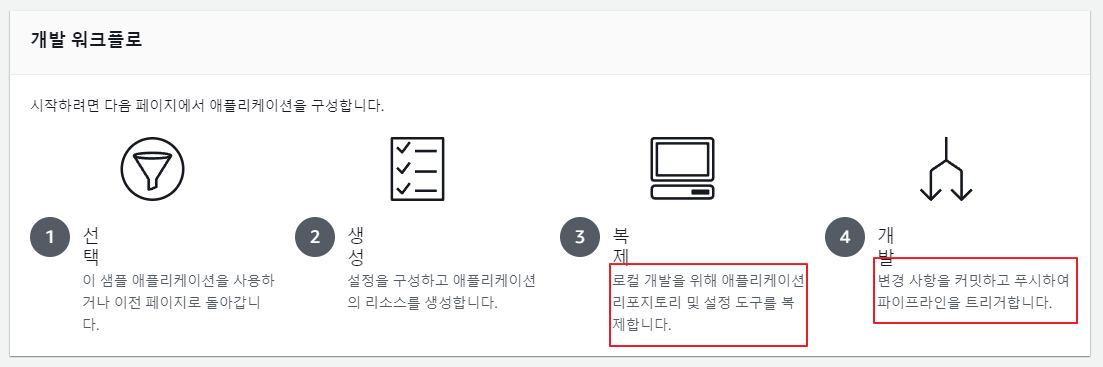
lambda의 워크플로
3. 토이 프로젝트로 가볍게 몇개 올리기에는 좋다
위와 마찬가지로 API 서버를 구축하려면 인프라 차원에서 세팅해야 하는 부분이 많다. 하지만 aws lambda를 활용하면 자동으로 git repository 생성부터 자동 배포까지 알아서 해준다. 이는 여러 인프라 세팅 단계를 스킵할 수 있기 때문에 매우 편하다.
4. https 설정, 도메인 연동 용이
aws에 붙어 있는 서비스라서 도메인, 거의 자동으로 https 프로토콜 적용이 가능하며 도메인 연동에 용이하다.
5. 함수별 호출 에러, 로그 조회 자동으로 상세화
직접 서버를 구축한 경우, 특별히 로깅 시스템을 구축하지 않았다면 에러가 발생했을 시 stacktrace 형식으로 에러가 발생한 부분을 찾을 것이다. 그러다 보면 정확히 원인이 발생한 지점까지 확인하지 못할 수도 있다 lambda는 함수단위로 에러 로그를 조회 할 수 있는 시스템이 기본으로 구축되어 있어 발생한 에러에 대한 파악이 쉽고 빠르다.
여기까지 봤을때는 와... 이걸 외 안씀? 이럴 수 있는데 극적 반전을 위해 단점을 아래 배치했다. 나의 한이 서린 원념을 담아서 작성해보겠다. 쭉 읽어보라
단점
실제 프로덕트에 쓰기에는 다양한 문제점을 동반
본 글의 요지이자 핵심인데 장점을 초월하는 실제 프로덕트에 쓰기에는 너무 많은 단점이 존재한다. 이는 개발을 어렵게, 불가능하게 만들 뿐더러 결과론적으로 더 오래걸리고 품질이 낮은 서비스가 될 가능성을 높여준다. 실제로 현재 다니고 있는 회사는 API의 dev 서버가 따로 존재하지 않으며, api 서버의 배포를 한 번 하는데 10~15분정도 걸리며, 구체적인 서버 커스터마이징이 불가능하다.
로우쿼리가 매 함수에 들어간다면...?
1. 구조 부재 : 지옥
모든 개발 프로젝트가 동일하지만... 람다라는 서비스는 초심자가 활용하게 된다면 가이드가 없기 때문에 함수형을 가장한 안티패턴이 될 가능성이 높다. 본 회사는 모든 함수에 로우쿼리가 들어가 있어 데이터의 CRUD를 재사용 하지 못하고 있다... ㅠㅠ (사실 모든 함수에 로우쿼리가 존재하는 것에 대한 문제인식이 안되는 것 부터 문제긴 하다.) 람다만이 가질 수 있는 함수형으로 인한 안티 패턴 특성이라 하면 함수 단위 하나가 스스로 돌아가기만 하면 되기 때문에 재사용성을 강요하지 않으면(기본이지만) 정말로 비슷한 함수임에도 불구하고 재사용을 1도 하지 않을 수 있다. 다시말해 일반적인 구조보다 함수마다 완전 다른 형태의 로직과 템플릿을 가질 수 있다.
chat gpt도 aws 람다는 로컬 디버깅이 안된다고 하신다.
2. 직접 디버깅 불가, 로깅 불편
치명적인 단점인데 직접 디버깅을 할 수 있는 방법이 없다. 브레이크포인트 찍으면 바로 잡을 문제를 하나씩 전부 로그찍게 만들어서 디버깅을 힘들게 만든다. 심지어 로그도 제대로 안돼서 매번 JSON.stringfy를 써야한다.
chat gpt 왈 aws 람다는 api마다 도커로 구동된다고 하신다.
3. 활용 불가능한 로컬 개발 환경
우선 api 서버를 로컬에서 구동하려면 docker가 필수적으로 실행되어 있어야 한다.(이건 딱히 문제가 안될 수 있다.) 그리고 api 주제에 각 api를 컨테이너로 구동하기 때문에 pc 리소스를 많이 잡아먹는다.(이것까지도 딱히 문제가 안될 수 있다.)
가장 크리티컬한 부분은 cold start라서 최초 호출 시 엄청오래 걸린다.(약 5~10초?) 이는 테스트가 불가능할정도이며 존재하는 모든 문서를 찾아봤는데 현실적으로 방법이 없다.(warm start -> api 개수가 너무 많으면 모든 api를 warm start로 구동하는데 하루종일 걸림) 결국 나도 내 신념을 포기하고 프론트엔드 개발자 분 보고 개발서버로 로컬개발 하듯이 사용하라고 했다.
그동안 어쩔 수 없이 꾹참고 로컬로 테스트 하던 상황이 생각나 너무 화나서 욕좀 한번 박겠다. 병신같은 서버리스 어플리케이션 모델~~ 나의 진심어린 분노가 여러분께 전달되어 한분이라도 이 똥을 안찍어먹을 수 있기를 바란다.
진행중 48분전 ... -> 지금 48분째 배포하고 있다는 뜻이다. 기네스감 아님?
4. 배포 개느림
아 욕 안할려했는데 저 사진 다시보니까 욕나옴 ㅋㅋ 시발진짜 급해 뒤지겠는데 언제끝날지도 모르고 뭐할때마다 개오래걸리고 후...
api가 100개정도 넘어가는 시점부터 배포하는데 거의 15분정도 걸린다. 이거 때문에 배포만 빨라도 금방끝내고 퇴근할걸 야근당한적도 몇번 있었다.
5. 자료가 많이 없다.
다른 이슈들에 비해 그리 크리티컬하지는 않으나 aws lambda에 대한 개발 자료가 월등히 적다. 초보 개발자라면 굉장히 고통받을 것이다.
짤막한 사용 팁
6개월동안 구르면서 직접 터득한 노하우들이다. 간략히라도 쓰려고 했는데 위에 단점쓰면서 화가 너무나서 이 글 게시물 조회수 좀 나오면 후속 게시물로 쓰겠다.
- 우측에서 플로팅으로 따라다님 - 게시물 내 h2태그 기준 목차 자동으로 추출 - 목차 클릭 시 해당 목차에 해당하는 영역으로 자동 이동 - 게시물에서 수정하거나 삽입 할 필요 없이 javascript로 후처리 하여 간편한 사용 - 만드는데 3시간 정도 걸렸음. 이걸 자기가 만든 것 처럼 무단배포 하는 착한 사람이 있으면 내가 이런 꿀정보를 공유 못함.
2. 적용 방법
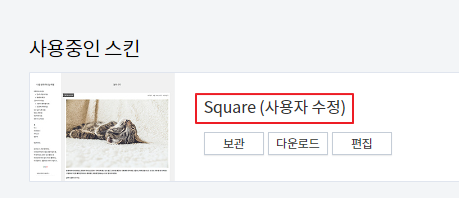
본인은 square 스킨을 사용 중, 다른 스킨을 사용하면 HTML 코드 구조가 다를 수 있으니 유의!
꾸미기 > 스킨 편집
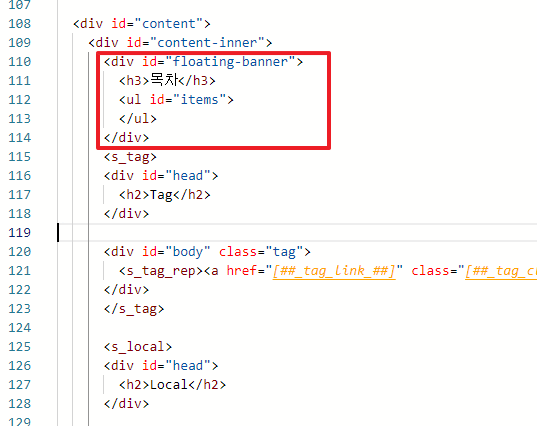
html 편집
이후 아래 3개의 코드를 적절한 위치에 추가해주면 된다. 이미지를 참고하여 위치를 확인 후 코드를 복사해서 넣어주자.