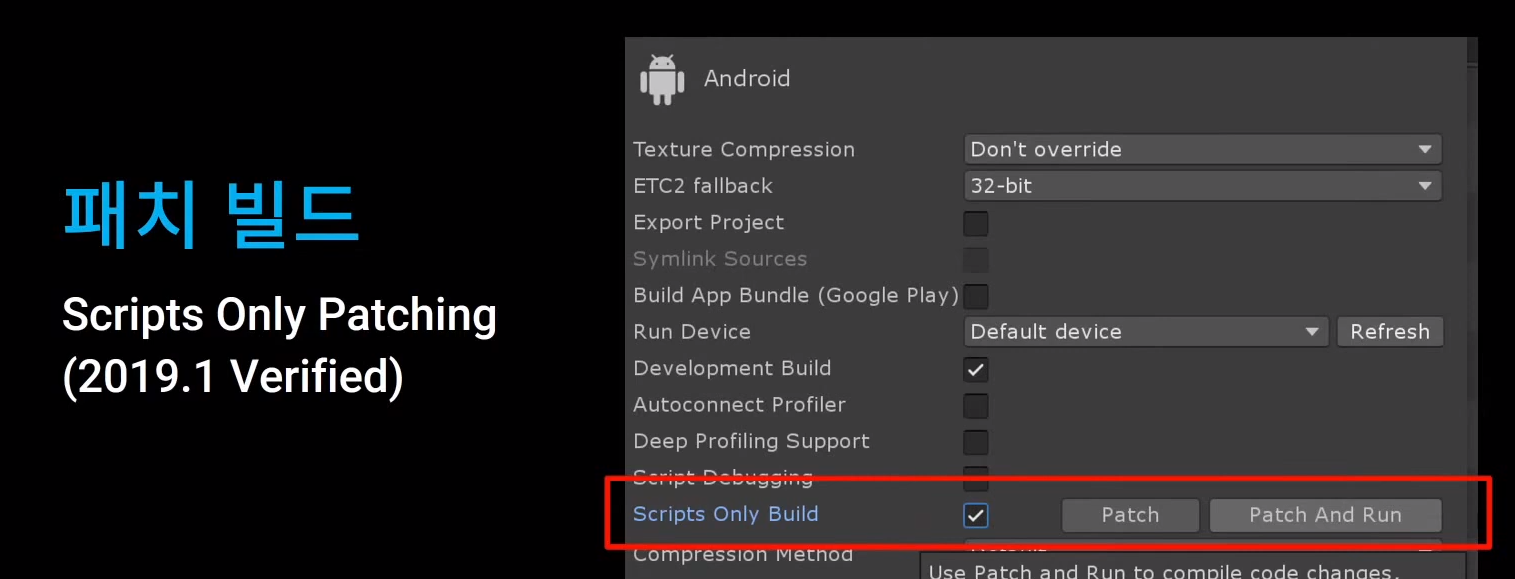
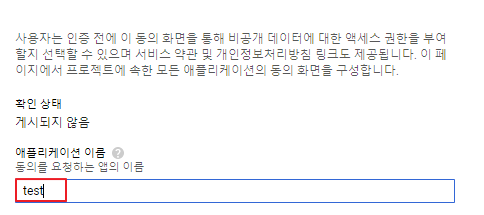
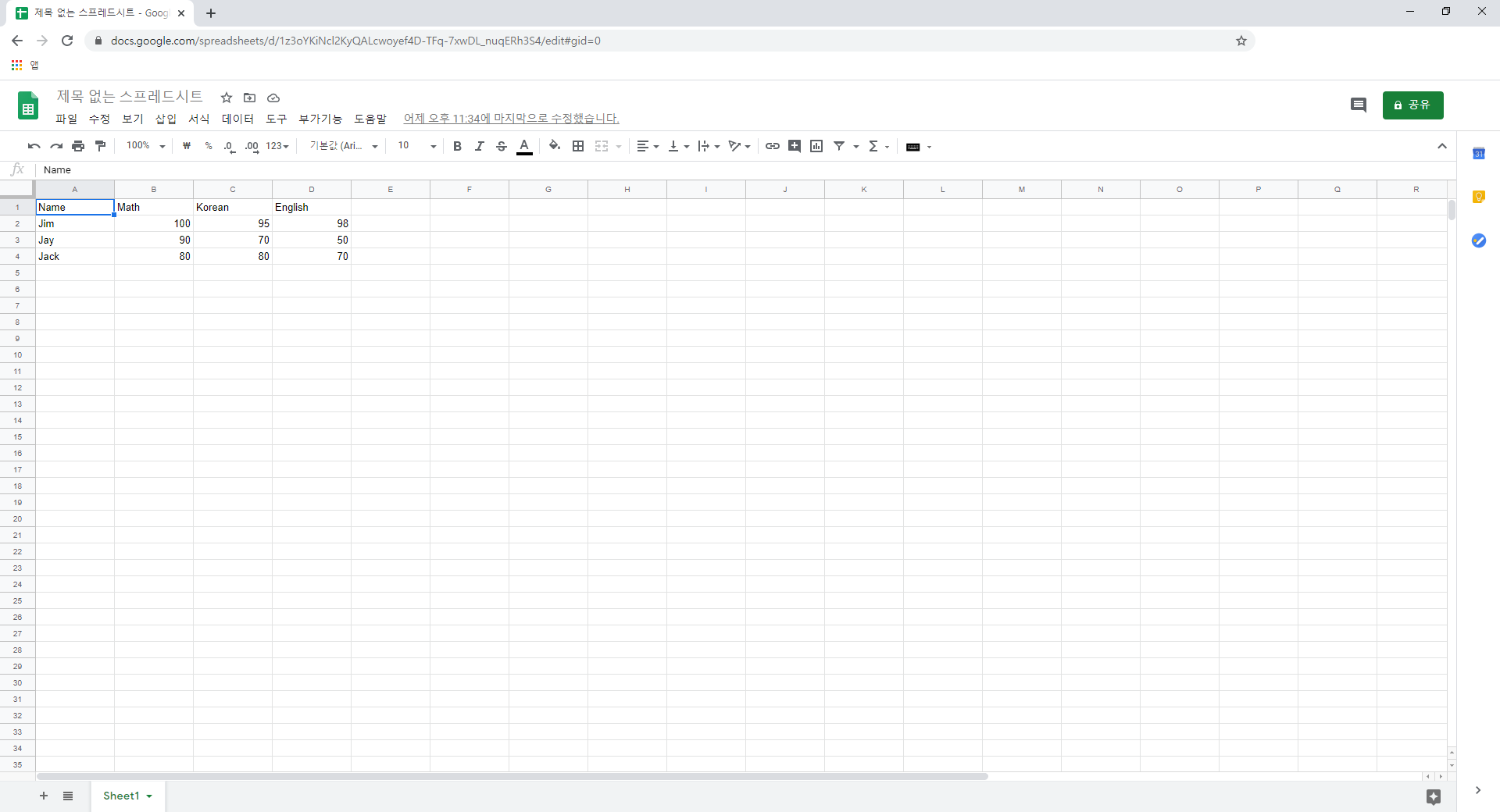
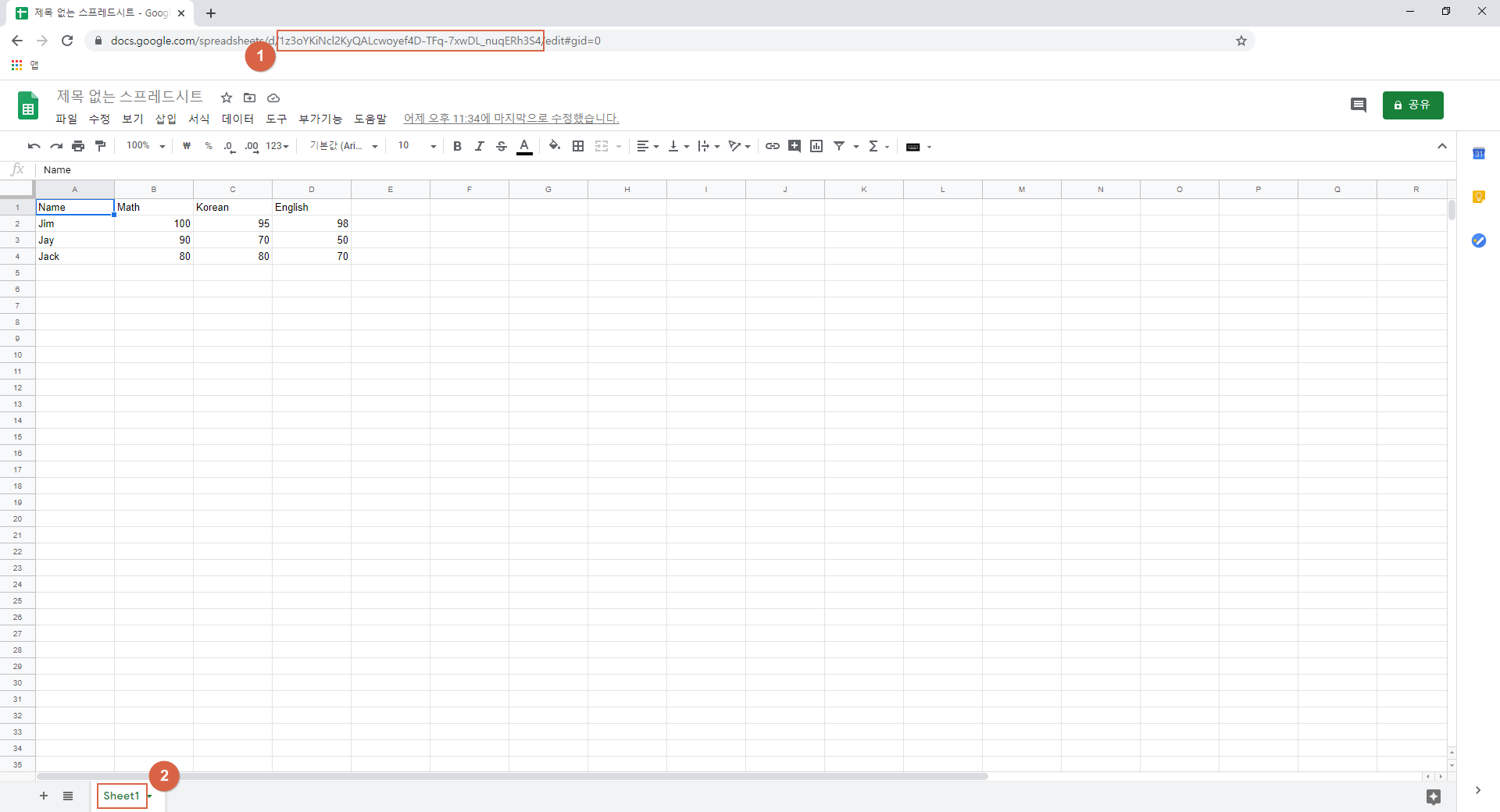
오늘은 네임드 개발자 오즈라엘님이 "성능 프로파일링과 최적화"라는 귀한 주제로 발표를 해주셨다. 두 시간짜리 영상을 열심히 보고 요약글을 올리는 나한테 감사하자
"쌍따봉 드립니다."
1. 프로파일링 유의사항
2. 유니티 프로파일러
2.1 다양한 병목현상
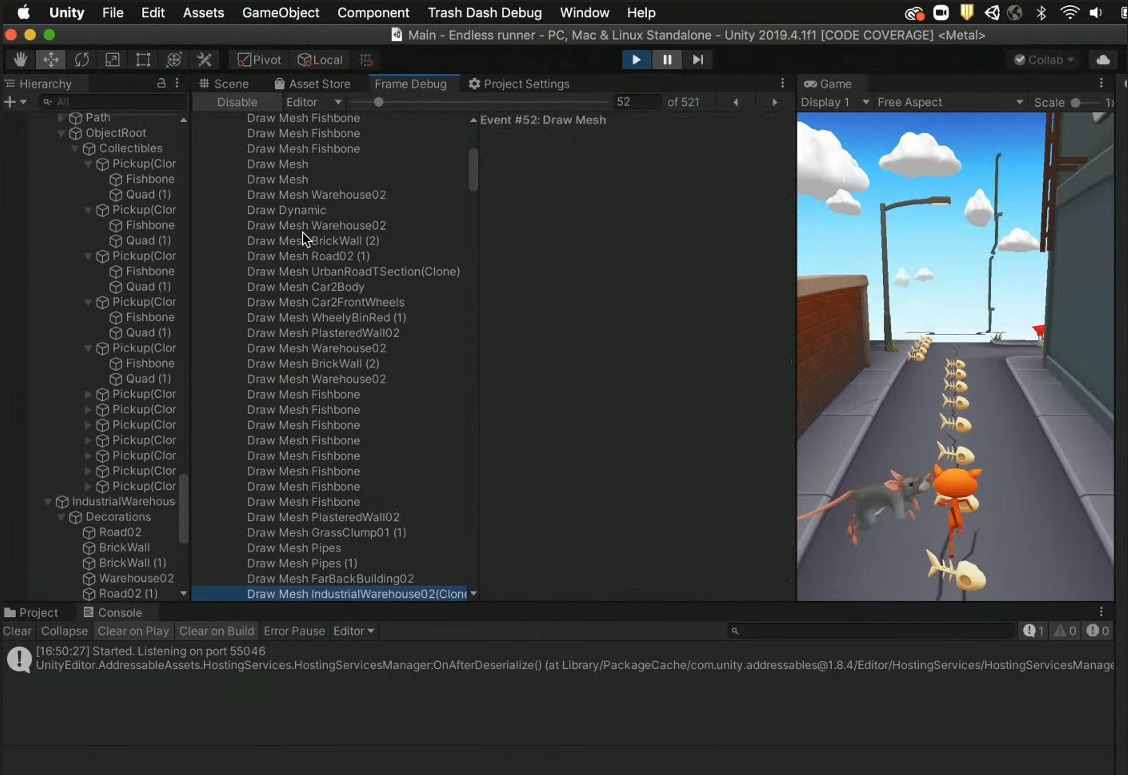
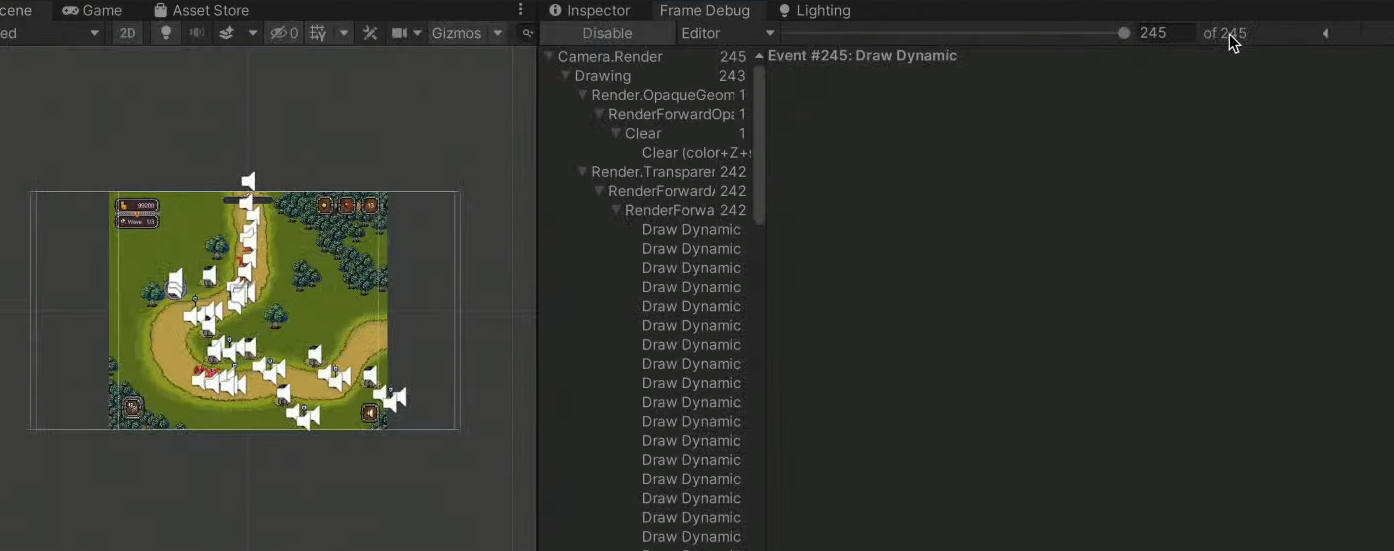
3. 프레임 디버거
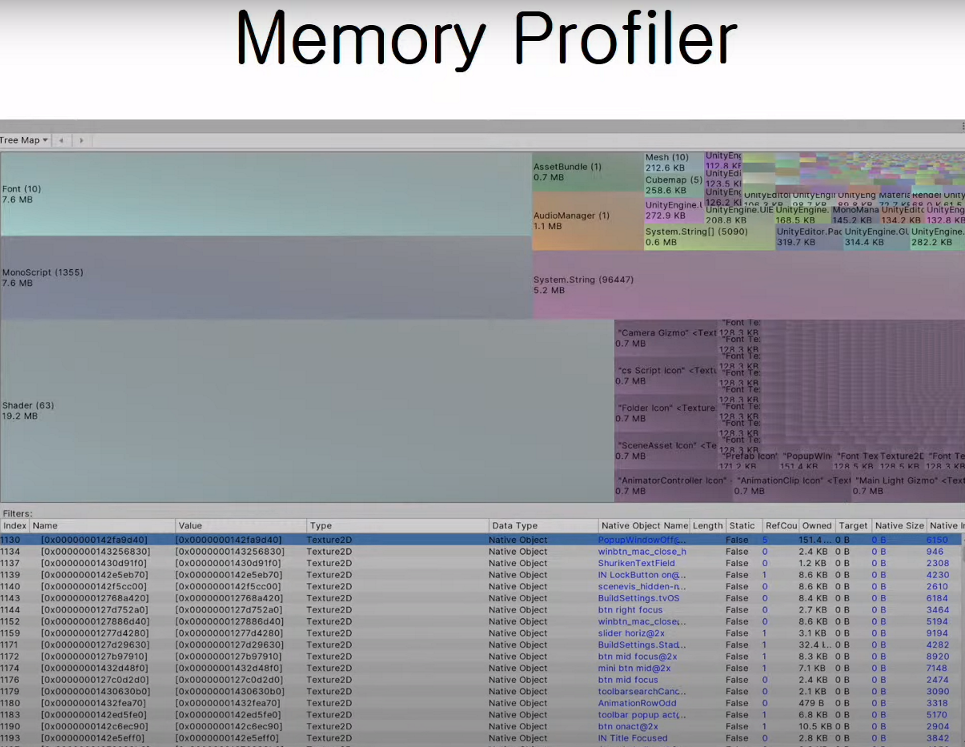
4. 메모리 프로파일러
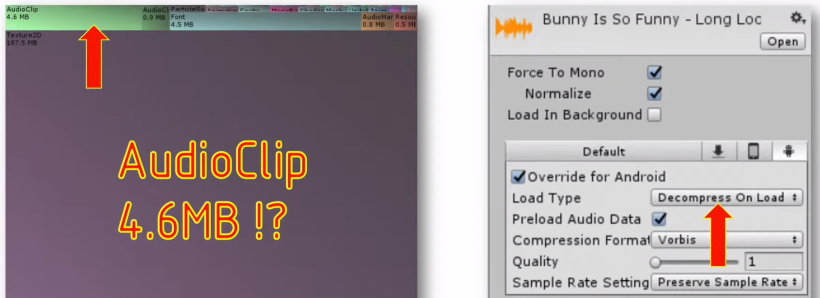
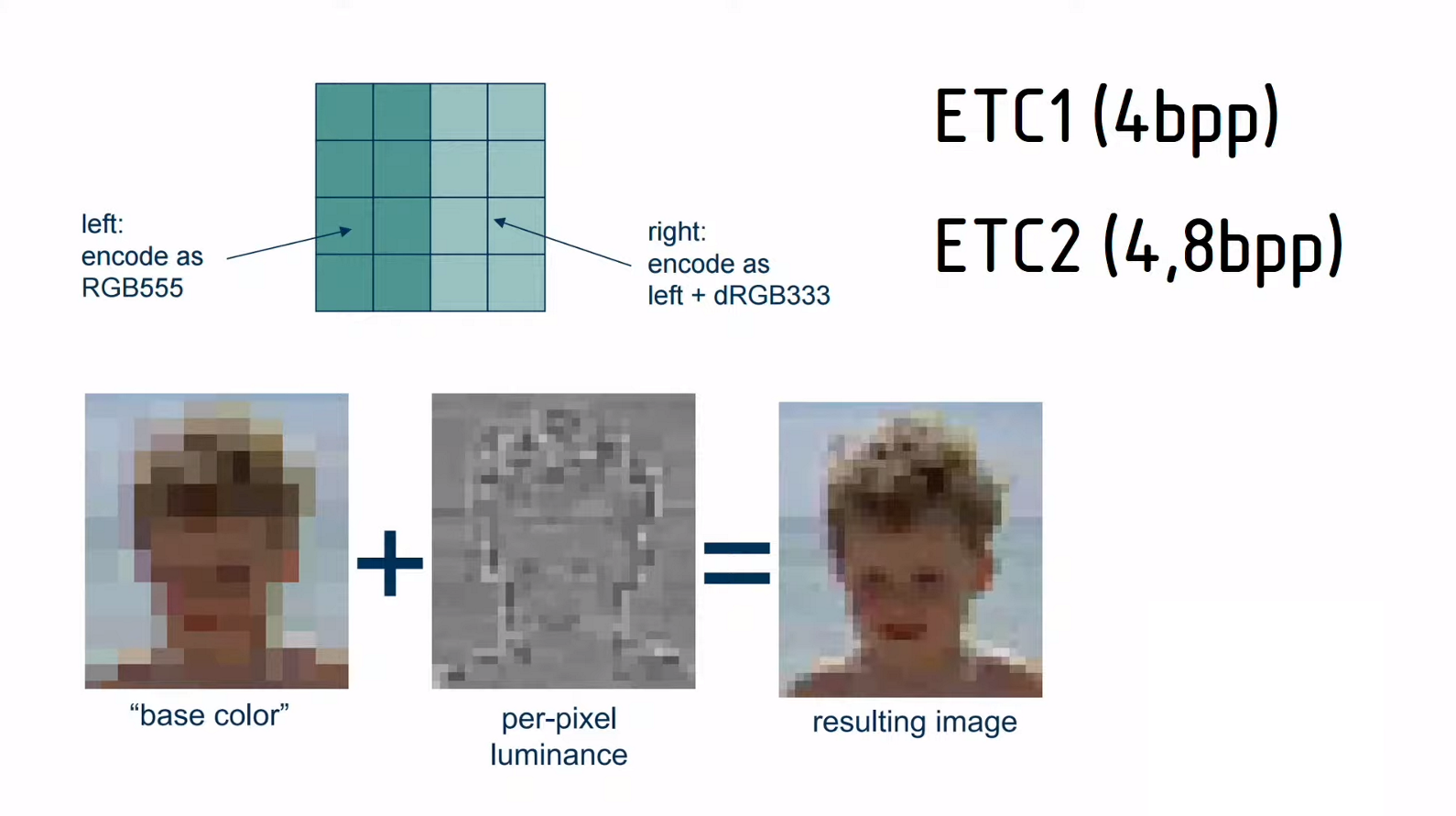
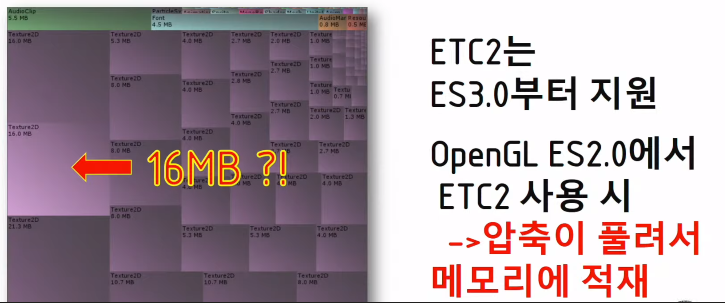
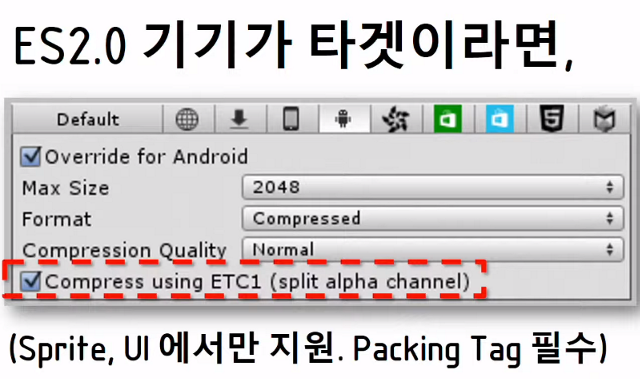
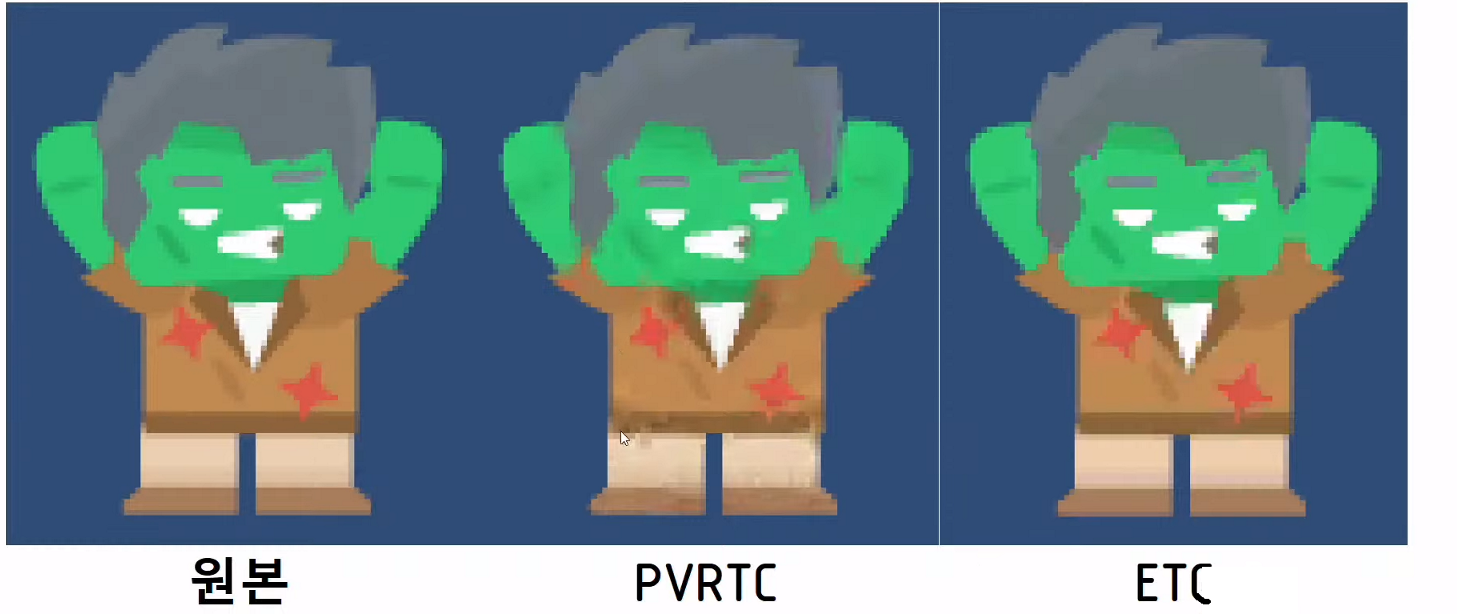
5. 텍스쳐 컴프레션
6. Xcode Instrument
7. 최적화 팁 & 트릭
1. 프로파일링 유의사항
타겟 플랫폼 선정
많은 팀이 간과하고 있는 것이 원래 최적화를 위해서 타겟 플랫폼과 타겟 디바이스를 정해야 한다.
무조건 좋은 퀄리티만 보여줄 수 없기 때문에 현실적으로 목표하고자 하는 디바이스와 플랫폼에 적합한 퍼포먼스를 보여줘야 한다.
사실 우리 회사도 타겟 플랫폼을 딱히 설정하고 개발을 시작하지 않는다. 하지만 가끔 게임 업계에서도 "ㅁㅁ게임은 동남아시아를 대상으로 한 게임이라서 저성능 기기를 타겟으로 개발을 한다...." 이런 말이 들려오는데 그런 환경이라면 합리적인 타겟 플랫폼 선정이 필수라고 생각이 든다.
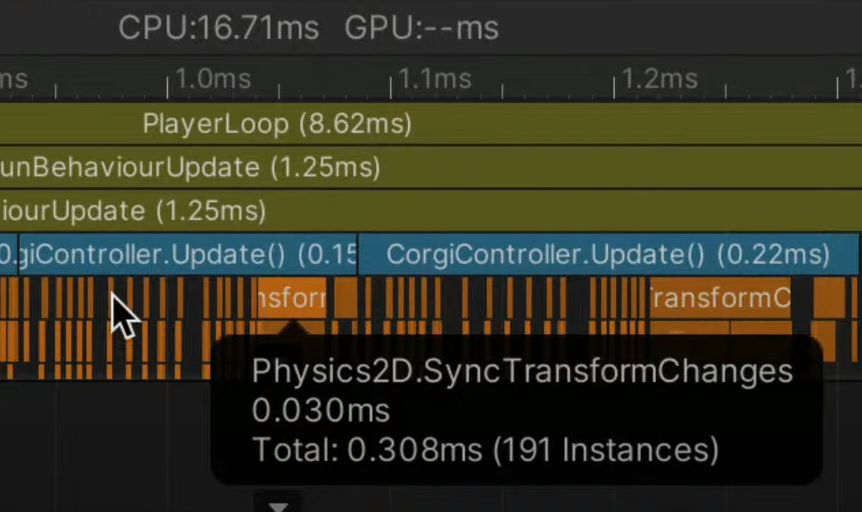
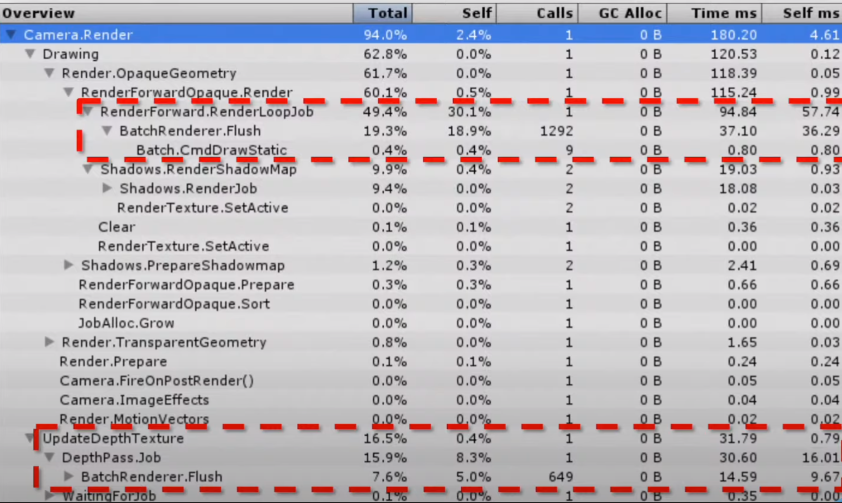
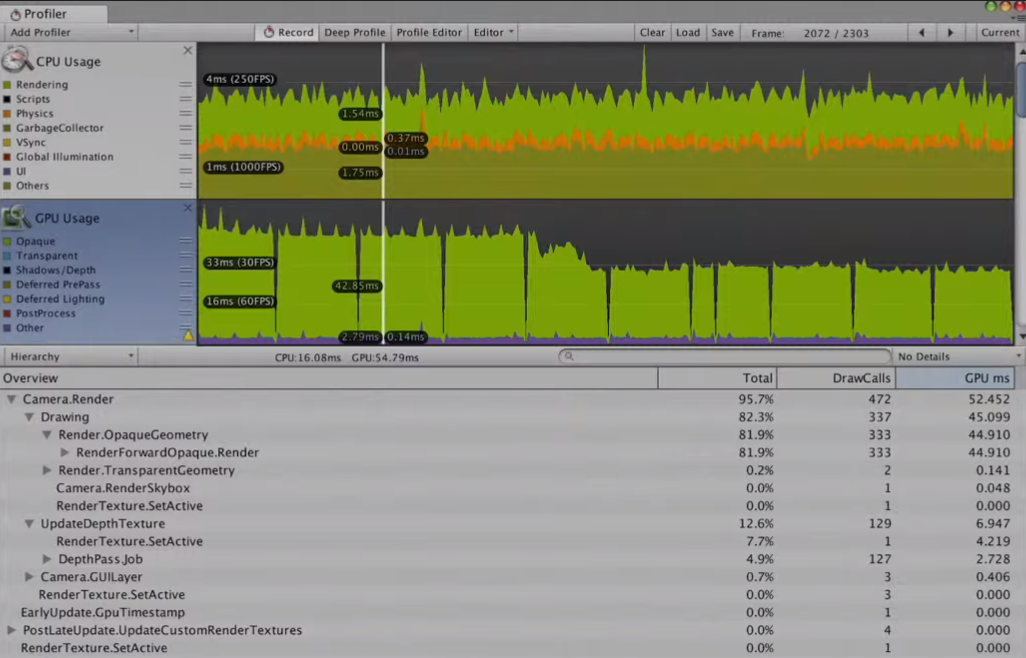
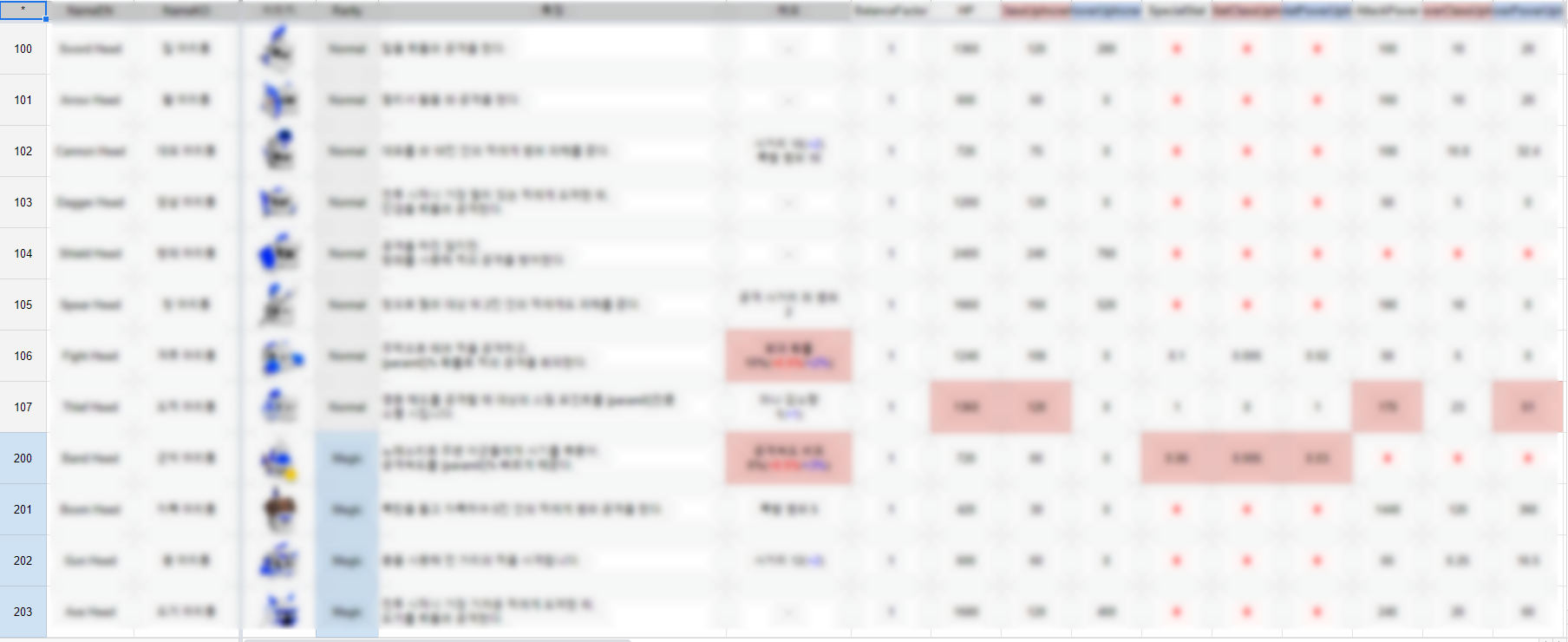
드로우 콜은 245며 캐릭터 하나를 그리는데 캐릭터 이미지, 그림자, 체력바, 체력바 백그라운드 총 4개의 드로우 콜이 발생한다.
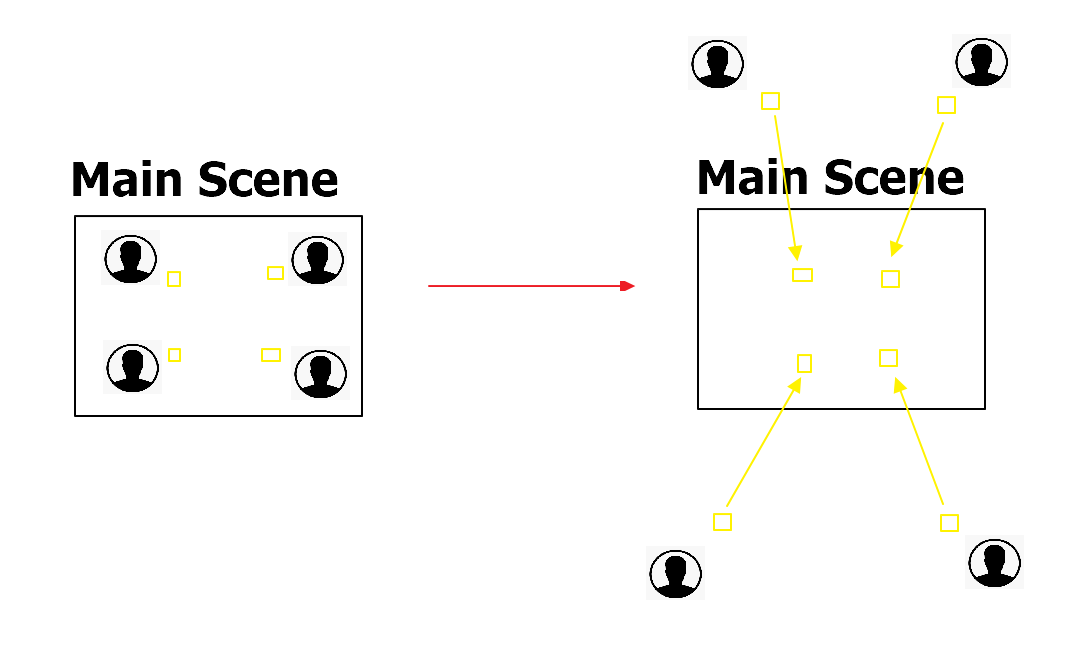
배칭이 전혀 안되어있다.
똑같은 성질의 이미지에 레이어를 추가해서 똑같은 애들끼리 똑같은 레이어를 적용시켜서 드로우 콜을 줄인다.
기존에는그림자하나를 그릴때 하나하나다그렸지만레이어를적용하면그림자가전부 한번에 다그려진다.
더나아가서스프라이트패킹, 배경레이어를추가하게된다면 드로우콜을 더줄일수있다.
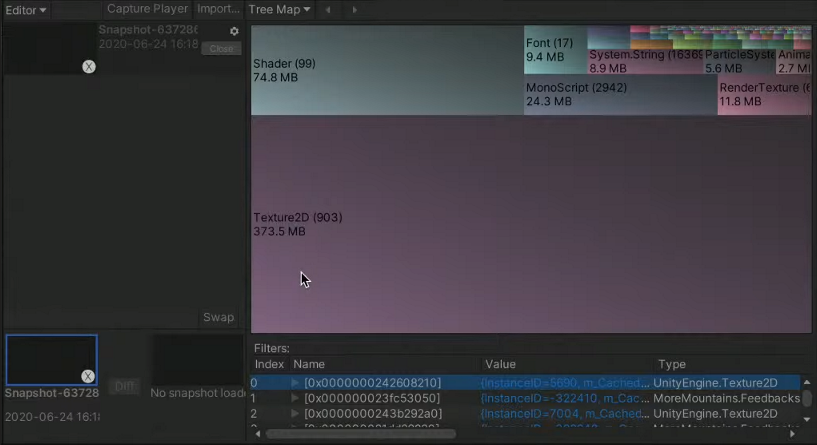
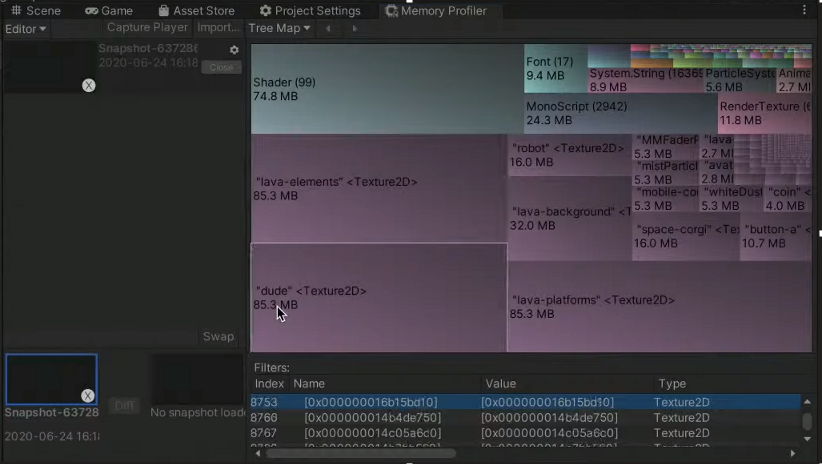
4. 메모리 프로파일러
메모리 관리는 항상 중요하지만 모바일에서는 특히나 중요하다.
PC에서는특정 어플리케이션에서 물리적으로 수용 가능한 메모리의 범주를 벗어나도 가상메모리를통해서해결할 수 있다.
그러나!모바일에서는메모리시스템이 PC와는달라서 특정 어플리케이션의 메모리 점유율이 높아지면 다른 어플리케이션의 메모리를 빼앗아서 사용하도록 설계되어있어서 메모리가 너무 커지는 순간 해당앱을 강제종료 시켜버린다강제 종료시켜버린다. (이와 같은 이유로 모바일에서는 로딩화면에서크러시가많이난다.)
실제로 내 게임도 아직 최적화를 거치지 않았는데 아이폰개발하다가 옛날기종에서 메모리 650mb 넘어가서 어플리케이션이 강제 종료당했다.
해당 설명을 들어가기 전에 앞서 스크립터블 오브젝트라는 것에 대한 이해를 하고 있어야 한다.
스크립터블 오브젝트는 추후에 설명하는 글을 써야겠다. 일단은 모른다면 친절한 글이 많으니까 이해하고 오도록 하자
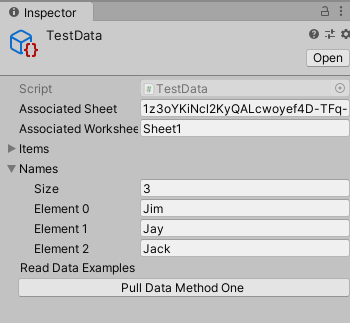
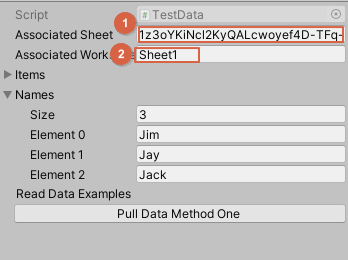
TestData라는 오브젝트의 스크립트를 열어보면 크게 두 부분으로 나뉜다.
테스트 데이터 객체에 대한 정의
public class TestData : ScriptableObject
{
public string associatedSheet = "";
public string associatedWorksheet = "";
public List<string> items = new List<string>();
public List<string> Names = new List<string>();
//1.3 긁어온 행 데이터를 조회하는 부분
internal void UpdateStats(List<GSTU_Cell> list, string name)
{
items.Clear();
int math=0, korean=0, english=0;
for (int i = 0; i < list.Count; i++)
{
switch (list[i].columnId)
{
case "Math":
{
math = int.Parse(list[i].value);
break;
}
case "Korean":
{
korean = int.Parse(list[i].value);
break;
}
case "English":
{
english = int.Parse(list[i].value);
break;
}
}
}
Debug.Log($"{name}의 점수 수학:{math} 국어:{korean} 영어:{english}");
}
}
생성된 테스트 객체의 커스텀 에디터(스크립터블 오브젝트의 인스펙터 부분이라고 생각하면 된다.)
[CustomEditor(typeof(TestData))]
public class DataEditor : Editor
{
TestData data;
void OnEnable()
{
data = (TestData)target;
}
public override void OnInspectorGUI()
{
base.OnInspectorGUI();
GUILayout.Label("Read Data Examples");
if (GUILayout.Button("Pull Data Method One"))
{
UpdateStats(UpdateMethodOne);
}
}
//1.1 GSTU_Search 객체를 생성하는 부분
void UpdateStats(UnityAction<GstuSpreadSheet> callback, bool mergedCells = false)
{
SpreadsheetManager.Read(new GSTU_Search(data.associatedSheet, data.associatedWorksheet), callback, mergedCells);
}
void UpdateMethodOne(GstuSpreadSheet ss)
{
//1.2 행 데이터를 긁어오기
foreach (string dataName in data.Names)
data.UpdateStats(ss.rows[dataName], dataName);
EditorUtility.SetDirty(target);
}
}
DataEditor부분에서 생성된 Pull Data Method One 버튼을 클릭하면 TestData의 UpdateMethodOne을 호출한다고 생각하면된다.(정확히는 TestDataEditor의 UpdateStats 함수를 호출하고 결과 콜백을 TestData의UpdateMethodOne으로 넘겨준다가 맞다. 해당 강좌의 주제는 엑셀이라서 이런 건 몰라도 크게 상관없다.)
data.Names에는 Jim, Jay, Jack이라는 행 데이터의 키 역할을 하는 값들이 들어있어서 ss.rows[dataName] 을 통해 행중에서 Jim, Jay, Jack 즉 3 개행의 데이터를 뽑아낸 것이다.
1.3 행 단위로 쪼갠 데이터를 열 단위로 다시 쪼개기
뽑아낸 행 데이터를 다시 열 단위로 쪼개서 조회해야 한다.
열 단위 데이터 조회하는 부분은 총 세 가지의 샘플 코드가 있다.
세 가지 형태의 샘플 코드를 한번 봐보자.
//1번 방식
internal void UpdateStats(List<GSTU_Cell> list)
{
items.Clear();
for (int i = 0; i < list.Count; i++)
{
switch (list[i].columnId)
{
case "Health":
{
health = int.Parse(list[i].value);
break;
}
case "Attack":
{
attack = int.Parse(list[i].value);
break;
}
case "Defence":
{
defence = int.Parse(list[i].value);
break;
}
case "Items":
{
items.Add(list[i].value.ToString());
break;
}
}
}
}
//2번 방식
internal void UpdateStats(GstuSpreadSheet ss)
{
items.Clear();
health = int.Parse(ss[name, "Health"].value);
attack = int.Parse(ss[name, "Attack"].value);
defence = int.Parse(ss[name, "Defence"].value);
items.Add(ss[name, "Items"].value.ToString());
}
//3번 방식
internal void UpdateStats(GstuSpreadSheet ss, bool mergedCells)
{
items.Clear();
health = int.Parse(ss[name, "Health"].value);
attack = int.Parse(ss[name, "Attack"].value);
defence = int.Parse(ss[name, "Defence"].value);
//I know that my items column may contain multiple values so we run a for loop to ensure they are all added
foreach (var value in ss[name, "Items", true])
{
items.Add(value.value.ToString());
}
}
방법은 다르지만 결국은 똑같은 시트의 Health, Attack, Defence, Items를 긁어오는 것이다.
그냥 이중에 하나만 잘 써도 충분하다. 나는 사실 첫 번째 방법만 계속 써서 다른 두 가지 방법이 있는지 몰랐을 정도로 잘 썼다.
internal void UpdateStats(List<GSTU_Cell> list, string name)
{
items.Clear();
int math=0, korean=0, english=0;
for (int i = 0; i < list.Count; i++)
{
switch (list[i].columnId)
{
case "Math":
{
math = int.Parse(list[i].value);
break;
}
case "Korean":
{
korean = int.Parse(list[i].value);
break;
}
case "English":
{
english = int.Parse(list[i].value);
break;
}
}
}
Debug.Log($"{name}의 점수 수학:{math} 국어:{korean} 영어:{english}");
}
위의 코드는 첫 번째 방법을 조금 변형한 것이다.
행 단위 데이터를 이루고 있는 열 단위의 데이터 중에서 switch문을 통하여 칼럼 값이 내가 필요한 Math, Korean, English 부분만을 긁어오는 것이다.
2. 데이터 매칭을 위한 키
이쯤에서 데이터 매칭을 위한 키가 필요하다는 부분을 한번 짚고 넘어가도록 하겠다.
당신이 엑셀 아래와 같은 데이터 시트가 있다고 하자.
체력
공격력
방어력
원숭이
99
9
9
군인
99
10
10
고릴라
9999
9999
9999
위 시트의 데이터를 긁어오는 것은 어렵지 않다 충분히 구현할 수 있다.
문제는 캐릭터를 생성할 때마다 시트를 긁어와서 넣어주면 너무 비효율적이기 때문에 한번 긁어와 놓고 어딘가에 저 데이터를 저장해놓고 사용해야 한다는 점이다.
어떻게 할 것인가? 한번 고민해보도록 하자.
우리 강의는 시청자가 고민할 시간을 제공한다.
바로 스크롤을 슉슉 내렸는가 사실 나라도 그랬을 것 같다.
여하튼 나의 경우에는 스크립터블 오브젝트를 만들어놓고 해당 스크립터블 오브젝트에 엑셀에서 긁어온 값들을 넣어놓고 사용한다. 그리고 그 스크립터블 오브젝트를 전부 다 들고 있고 관리하는 로컬 데이터베이스 클래스가 있다.
요 구조에 대해서는 나중에 또 실습을 해볼 것이다.
그전에 지금 얘기하고 있는 중요한 부분 데이터 매칭을 위한 키를 정해야 한다는 점에 대해서 얘기하겠다.
엑셀에서 데이터를 긁어왔는데 긁어온 데이터는 스스로 목적지를 찾아서 들어가 주지 않는다.
즉 유니티 내부에서 저장해놓을 곳과 엑셀 데이터의 매칭을 위한 약속을 해야 한다는 것이다.
이 부분을 깔끔하게 정하지 않으면 더러운 하드코딩으로 악순환이 돼버릴 수 있다.
기본적으로는 절대로 변하지 않는 데이터에 대한 키 값을 정해야 한다.(또한 키가 키 외에 다른 역할을 하지 않도록 하자)
아래 표를 보면 원숭이, 군인, 고릴라는 키 역할을 하면서 동시에 게임 내부에서 오브젝트 명까지 맡고 있다. 충분히 바뀌지 않을 수 있지만 오브젝트 명은 언제든지 바뀔 수 있다. 그렇기 때문에 분리를 해야 한다.
체력
공격력
방어력
원숭이
99
9
9
군인
99
10
10
고릴라
9999
9999
9999
↓
이름
체력
공격력
방어력
char_monkey
숭숭이
99
9
9
char_solider
군인
99
10
10
char_gorilla
고륄라
9999
9999
9999
이름
체력
공격력
방어력
001
숭숭이
99
9
9
002
군인
99
10
10
003
고륄라
9999
9999
9999
이런식으로 분리를 하자는 것이다. 기왕이면 키만 봐도 어떤 데이터인지 알 수 있는 char_monkey 형태가 좋은 것 같다. 나는 001 형식으로 인덱스 값을 부여해서 사용하는데 문제는 딱히 없다.
이미 구글에 관련 게시물들이 올라와있는데 왜 또 쓰는 거냐?(이 게시물은 다른 게시물들과 뭐가 다른 거냐?)
나는 원래 이미 다뤄진 이슈는 잘 안 다루지만 구글 스프레드 시트 연동하는 포스팅을 봤는데 대부분이 정말 초기 세팅 부분만 정리해놓고 그 이후 활용에 대한 내용이 없었다. 그 부분을 널리 알리고자 쓰게 되었다.
어떤 경우에 쓰는가?
게임을 혼자서 만들면 굳이 구글 엑셀 시트까지 연동할 필요 없이 넣어주면 된다. 협업 환경에서 기획자가 밸런스나 수치 데이터를 조절할 때마다 내가 할 수는 없으니까, 이를 쉽게 조절할 수 있도록 만드는 경우에 사용한다.
어디까지 구글 시트로 연동해야 하는가?
행여나 구글 시트로 연동한다고 했을 때 게임의 수치적인 모든 것을 스프레드 시트로 관리하는 것이 꼭 능사가 아닐 수도 있다.
선별적으로 생각해서 정말로 시트로 관리할 가치가 있는 부분만 시트로 관리하도록 하자. 별로 수정할 일도 없는 부분을 구글 시트로 빼느라 고생하지 말자는 뜻이다.
참고사항
참고로 이번 주제에서는 데이터 읽기만 할 것이다. 쓰기는 안한다.
주변의 조언을 종합해서 짧게 말하자면 엑셀 데이터를 긁어오는 것은 개발단계, 관리수준에서 데이터를 쉽게 관리하기 위함이지 게임이 출시되고 나서 인게임에서 엑셀로 데이터를 긁어오는 상황을 위한 것이 아니다.(보안 취약) 따라서 엑셀 시트와 관련된 부분을 전처리하는것이 좋겠다.
수많은 글들이 노드의 메모리 누수에 대한 글들을 설명하고 해결방법, 대안을 포스팅했지만 정말 겉만 번지르르하고 도움이 안 됐다.
사실 좀 화가 났다. 왜냐면 나는 개발을 다 해놓고 앱을 돌려보니까 메모리 누수가 발생했는데 어디서 누수가 발생했는지 감도 안 잡히고 찾아보면 대부분의 게시물이 '메모리 누수는 스택과 힙 영역에서 머시기머시기 -> 정말 간단한 테스트 코드로 메모리 할당된 거 보여주면서 요런 식으로 메모리 누수가 발생하고 이렇게 하면 안 됩니다.~~' 이렇게 끝난다. 뭐 어따쓰라고 ㅡㅡ
그래서 직접 부딪혀보면서 메모리 누수를 찾고 해결해내었다. 결론부터 말하자면 개발을 엄청 잘한다고 메모리 누수를 피해 갈 수 있는 것이 아니다. 왜냐면 정말 많은 사람들이 사용하는 라이브러리에서도 엄청난 메모리 누수가 발생하였기 때문이다.
즉 당신은 메모리 누수가 발생하였으면 직접 덤프를 까보며 분석하고 해결하는 능력을 길러야 한다.
앞으로 포스팅할 글들은 실제 개발하다가 메모리 누수가 발생하였고 누수에 대한 확인, 해결방법을 제시하도록 하겠다.
꽤나 가치 있는 게시물이 될 것이라고 장담한다.
2. 메모리 누수란?
메모리 누수에 대한 간단한 설명을 하겠다.
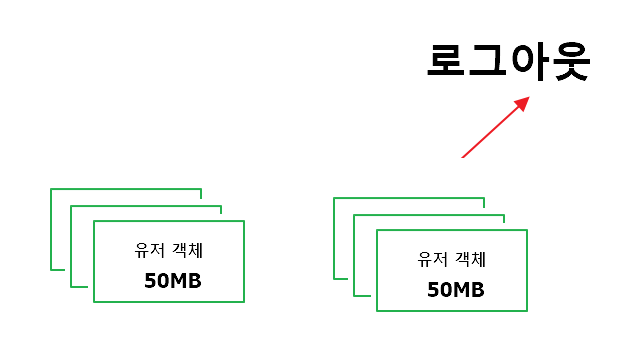
당신은 온라인 게임을 만들었다. 한 명의 유저가 접속하면 유저에 대한 객체를 생성하는데 1MB가 필요하다.
축하한다. 당신이 만든 온라인 게임에 유저 100명이 들어왔다. 100MB의 메모리를 할당받았다.
안타깝게도 당신의 게임이 너무 빨리 질려버린 탓에 50명의 유저가 종료를 해버렸다.
그래서 50개의 유저 데이터를 파괴하고 50MB의 메모리를 다시 돌려받아야 한다.
GC는 이러한 과정 속에서 사용이 완료되고 다시 사용할 수 있도록 메모리를 수거하고 다시 사용 가능하도록 관리한다.
여기서 문제가 발생한다. 정체불명의 이유로 인해서 유저 50명이 접속을 종료해도 GC가 판단하기에 50명의 데이터를 담 고 있던 메모리가 아직 사용이 완료됐다고 판단하지 않아서 메모리를 수거하지 않고 계속 남아있는 것이다.
이것이 계속 반복되면 결국 앱은 무한대로 메모리를 점유하게 될 것이고 언젠가 앱이 강제로 종료될 것이다.
메모리 할당 -> 사용 끝 -> GC가 수거 못함 -> 아무도 사용 안 하지만 계속 할당된 채로 남아있음 -> 반복 -> 서버 폭발
3. 메모리 누수 확인
그러면 실제 개발하다가 메모리 누수가 발생하면 어떻게 되는지 확인해보자
일단 먼저 본인의 앱에서 메모리 누수가 발생한다는 것을 인지해야 한다.
왜냐하면 당신의 앱에서도 충분히 메모리 누수가 발생하고 있지만 그 정도가
나는 메모리 누수에 대한 개념이 부족한 때라서 메모리 누수를 인지하는데 상당히 오래 걸렸다.
작업 관리자에서 Node가 차지하는 메모리를 보면 2000mb인 것을 볼 수 있다. 말도 안 되는 상황이지 않는가?
4. 노드 크롬 디버거
먼저 노드의 메모리 누수를 확인하기 위해서는 노드 크롬 디버거를 사용해야 한다.
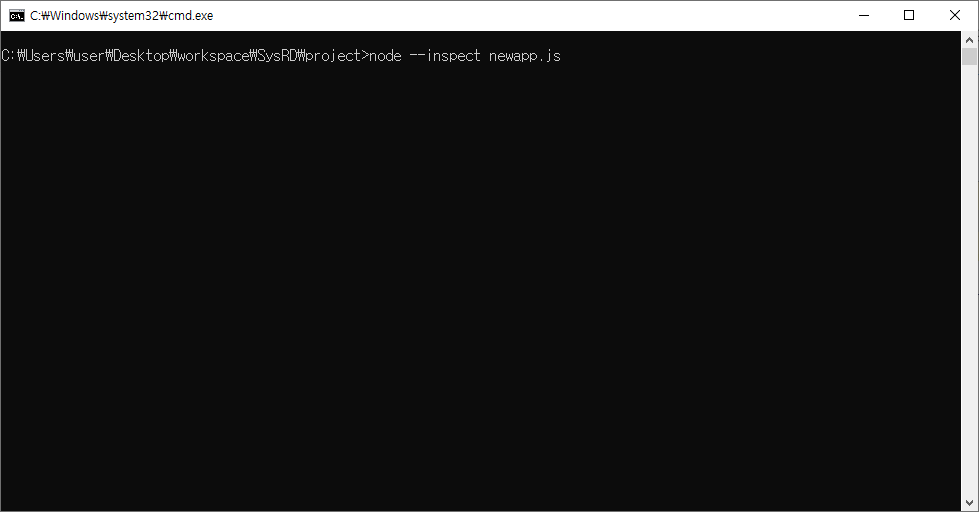
노드 크롬 디버거를 사용하는 방법은 다음과 같다.
node --inspect 시작 파일
그러면 위와 같은 메시지가 추가로 나온다. 포트가 9229여야 하는데 꼭 9229일 필요는 없지만 구글 크롬에서 기본값으로 부착되는 포트가 9229라서 편하다
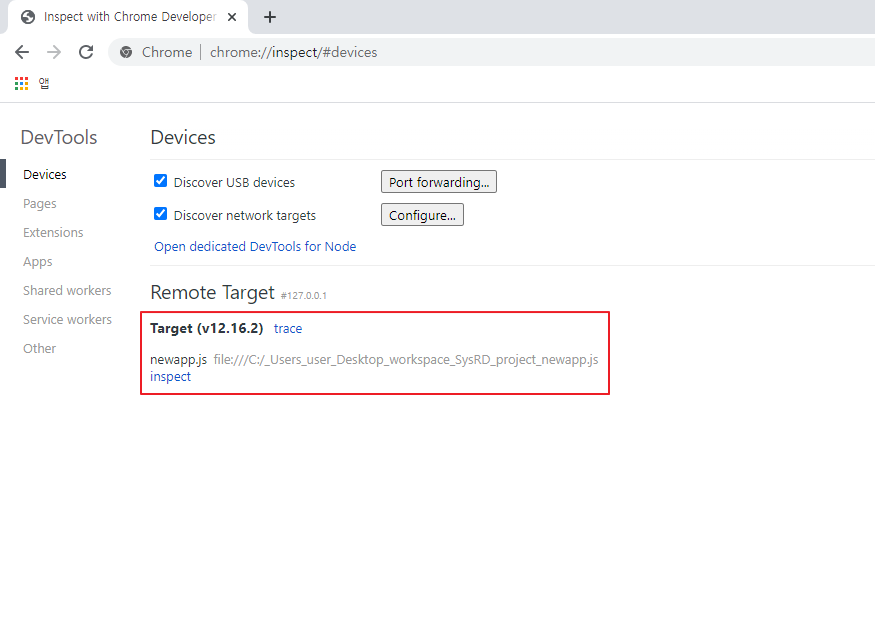
구글 크롬으로 들어간다.
URL에 chrome://inspect로 접근한다.
위와 같이 하단에 구동 중인 서버가 보인다. inspect를 눌러서 디버거를 켠다.
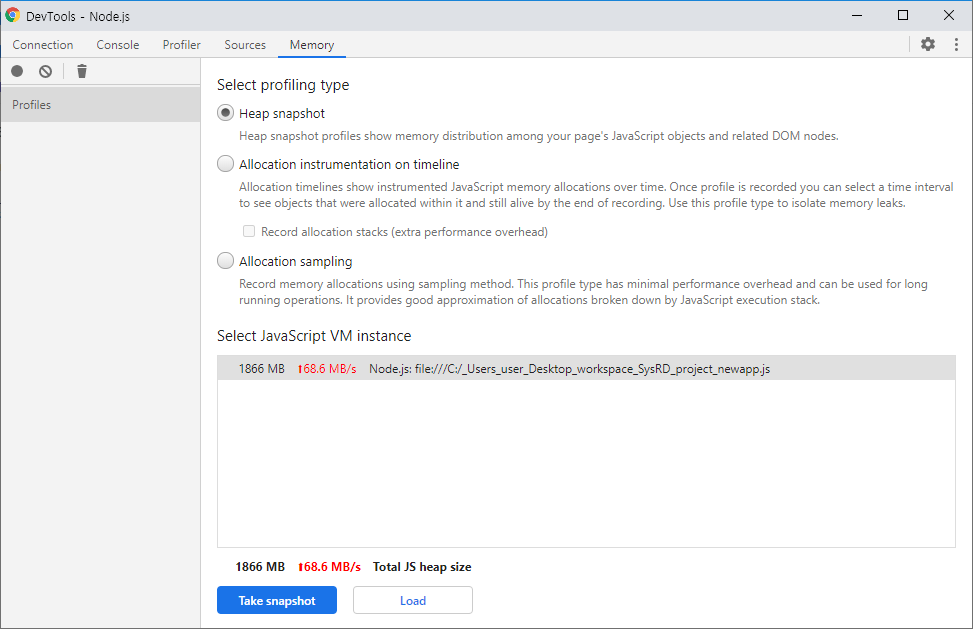
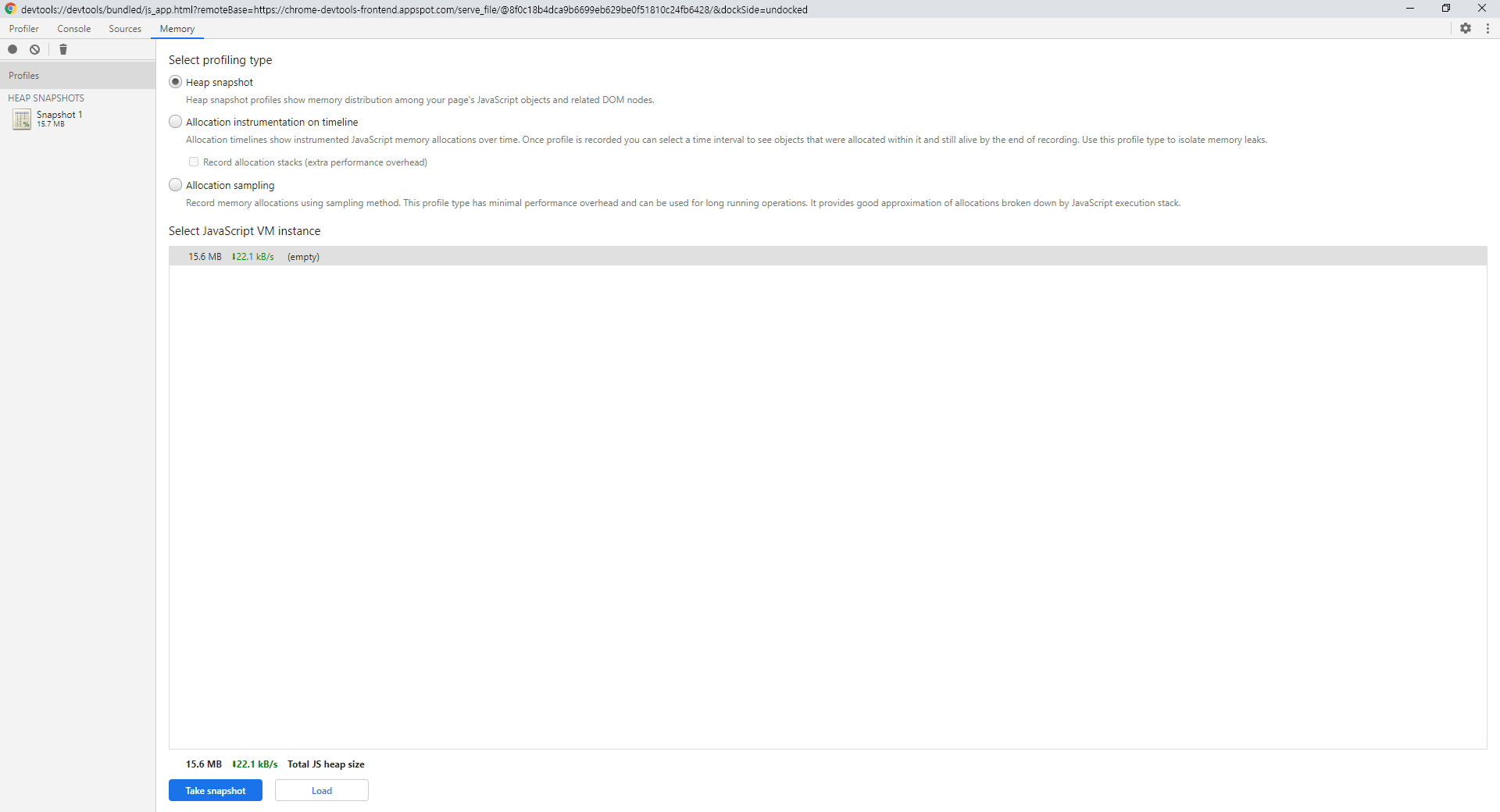
Memory > Profiles의 메모리 부분을 보면 현재 애플리케이션이 사용 중인 메모리를 실시간으로 볼 수 있다.
저 상태에서 메모리 부하를 일으키는 작업을 실행해보자 메모리가 하늘 높은 줄 모르고 계속 치솟는다.
그러다가 앱이 멈추면서 특정 부분에서 break를 한다. 우측을 보면 Paused before potential out-of-memory crash라고 나와있다. 메모리 부하가 심해서 임종 직전에 멈춘 것이라고 한다.
5. 누수 발생 확인
메모리 누수가 발생하는 원인을 확인해보는 여러 가지 방법을 설명하도록 하겠다.
메모리 스냅샷을 이용하여 부하를 일으키는 메모리는 어떤 종류인지 확인해보겠다.
메모리 부하를 일으킨 다음에 메모리 스냅샷을 떠서 용량이 많이 차지하는 덩어리를 한번 까보는 것이다.
일단 아무것도 하지 않은 위 상태에서 스냅샷을 한번 찍는다.
이전 단계와 마찬가지로 부하를 일으켜보고 어느 정도 됐다 싶으면스냅샷을 한번 더 찍는다.
두 개의 스냅샷이 저장됐다.
각 스냅샷의 Statics를 확인해보자.
좌측은 정상적인 어플리케이션 메모리의 분포 상황이고 우측은 딱봐도 이상하리만큼 Strings로 꽉찬 메모리 분포 상황이다. 이정도면 엄청나게 많은 string을 만들어놓고 gc 처리를 못해서 메모리 부하가 생긴다고 킹리적 갓심이 가능한 상황이다. ㅇㅈ?ㅇㅈ
이번에는 저 많은 string이 어떤 부분에서 발생하는지 확인해보도록 하자.
앱을 다시 시작하고 부하를 주지 않은 상태에서 Allocation sampling 을 선택하고 Start를 누르고 어느정도 부하가 되면 Stop을 눌러서 결과를 살펴보자.
Allocation sampling은 메모리 부하를 주는 자바스크립트의 메쏘드를 살펴보는 기능이다.
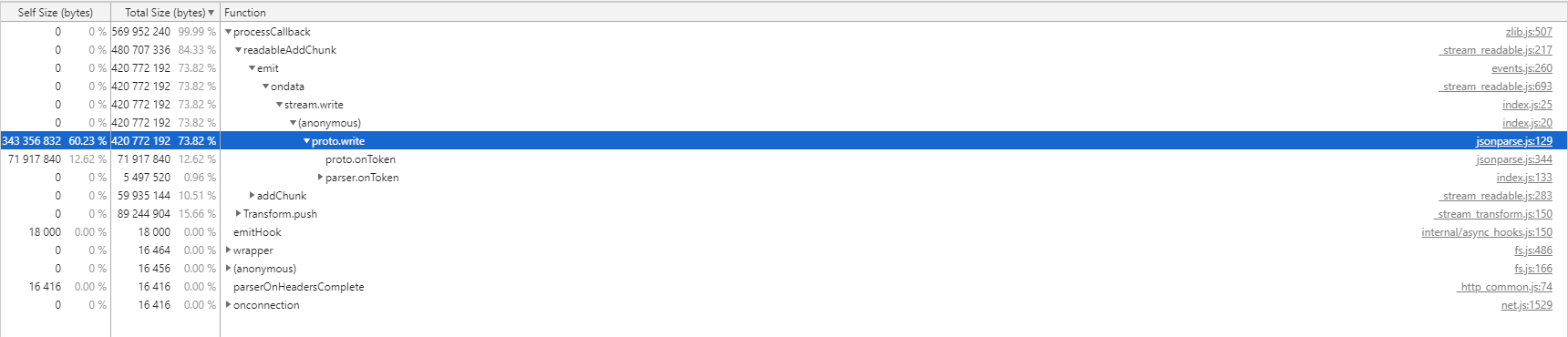
Tree형식으로 확인해보자
혼자서 무려 메모리 사이즈의 99.99%를 차지하는 불순한 녀석이 보인다. 저 녀석의 하위 트리를 따라내려가보면서 쭈욱 살펴보도록 하자
jsonparse라는 내가 설치한 라이브러리가 해당 문제를 일으키고 있으며 해당 라이브러리의 문제를 일으키는 메쏘드들을 확인할 수 있다.
그러면 마지막으로 메모리 누수가 발생하는데 어떤 형태의 데이터가 쌓이는지 그 값들을 직접 확인해보자
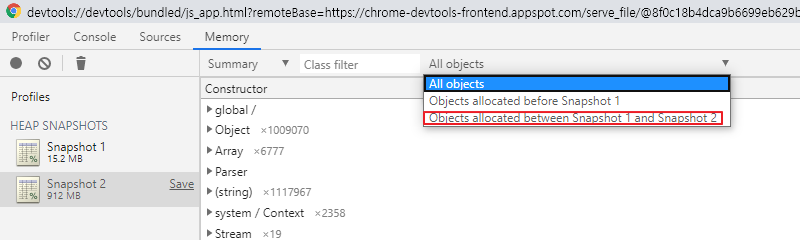
다시한번더 어플리케이션의 초기상태, 부하상태의 스냅샷을 각각 찍어보자
All Obejcts를 두 스냅샷 사이이로 해주고 Summary를 Comparison으로 해주자
그러면 두 스냅샷 사이에서 생성된 데이터를 볼 수 있다.
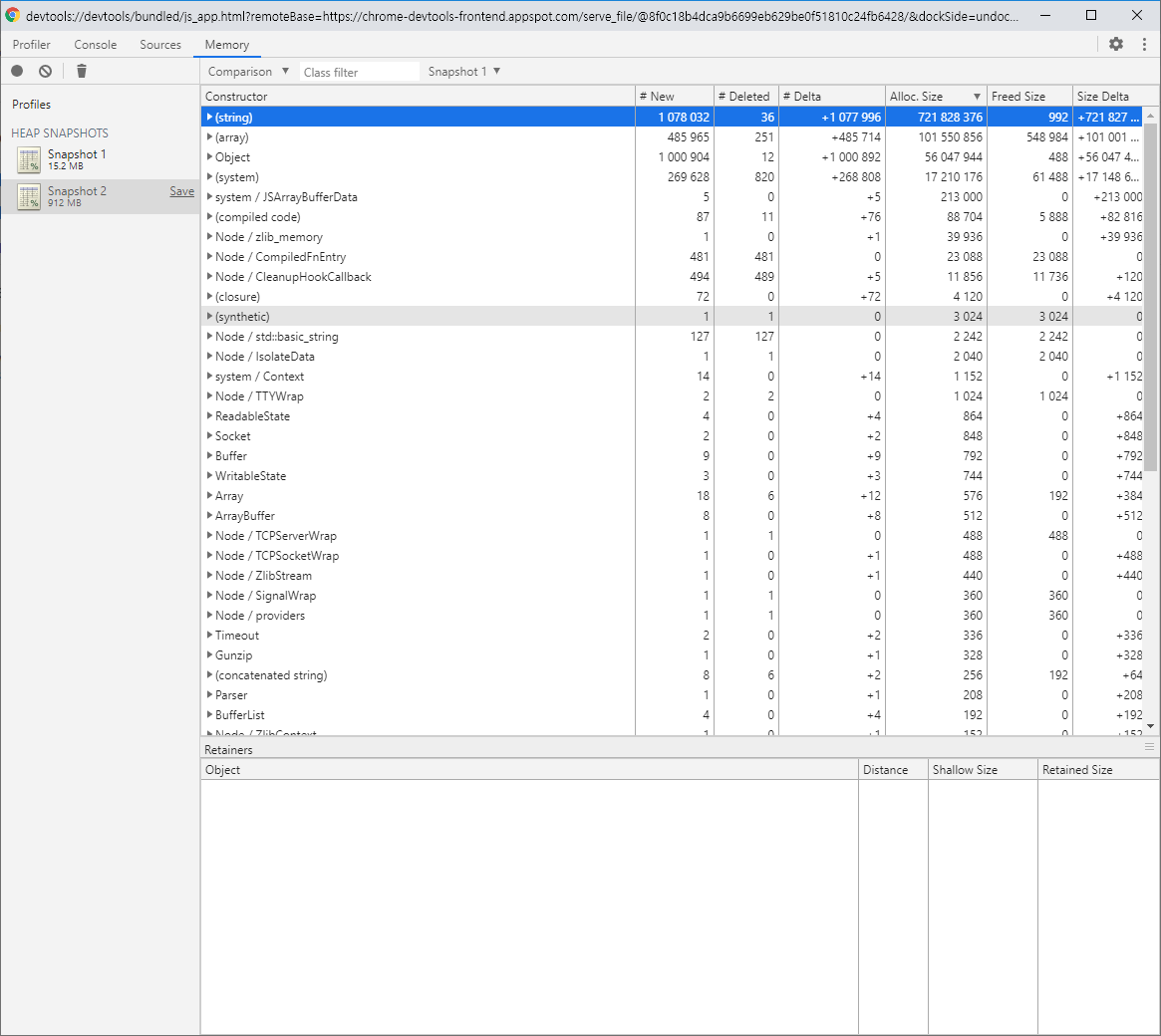
Alloc.Size로 내림차순 정렬을 하고 상단의 트리를 열어보자
그러면 어 저거 내가 생성한 데이터인데 왜 저기있지? 싶은것이 있으면 원인을 찾은 것이다.
분명 저 데이터는 처리되고 말소되어서 GC가 수거해가야하는데 수거하지 못하게끔 어딘가에 계속 맞물려있는 것이다.